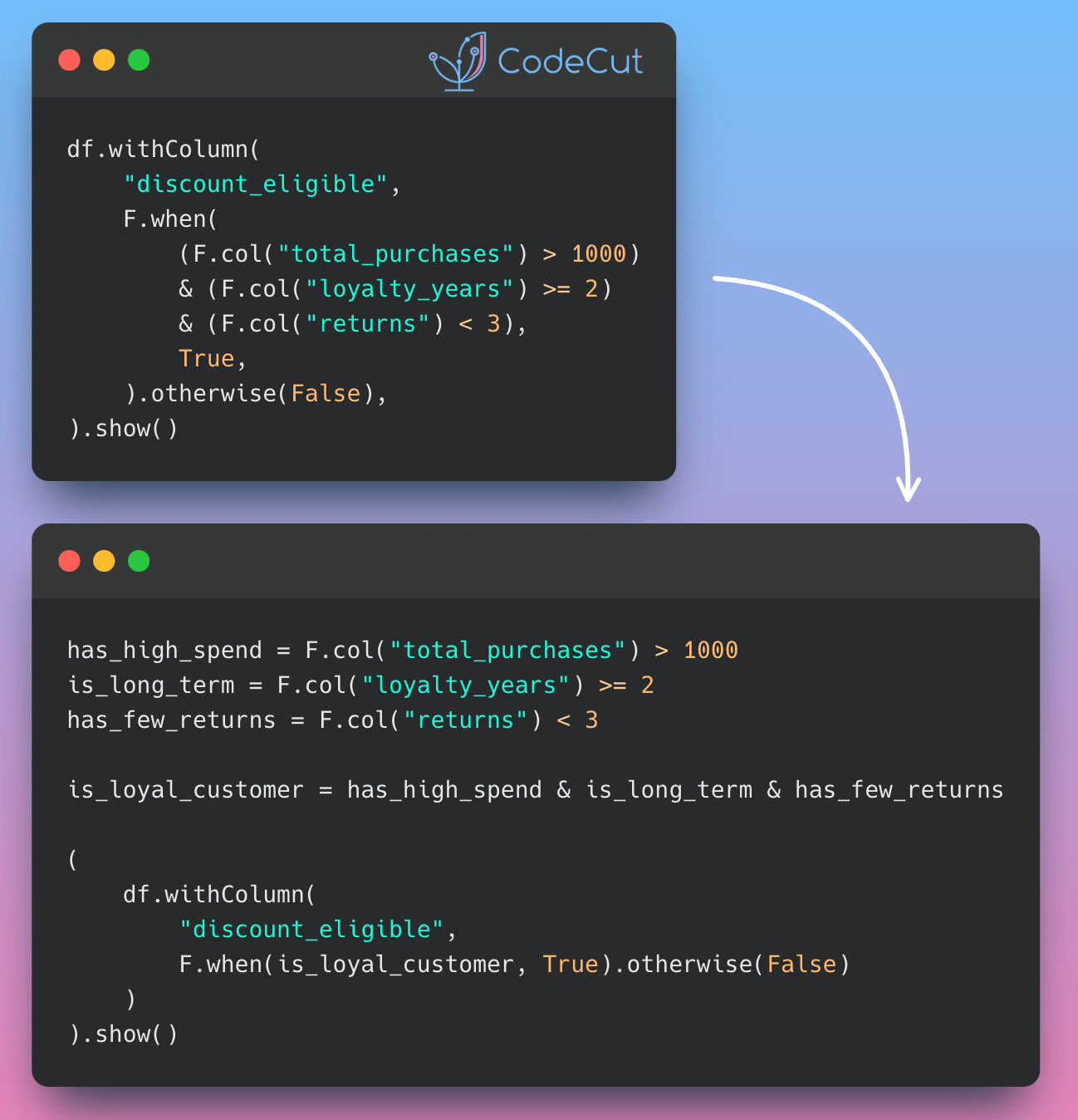
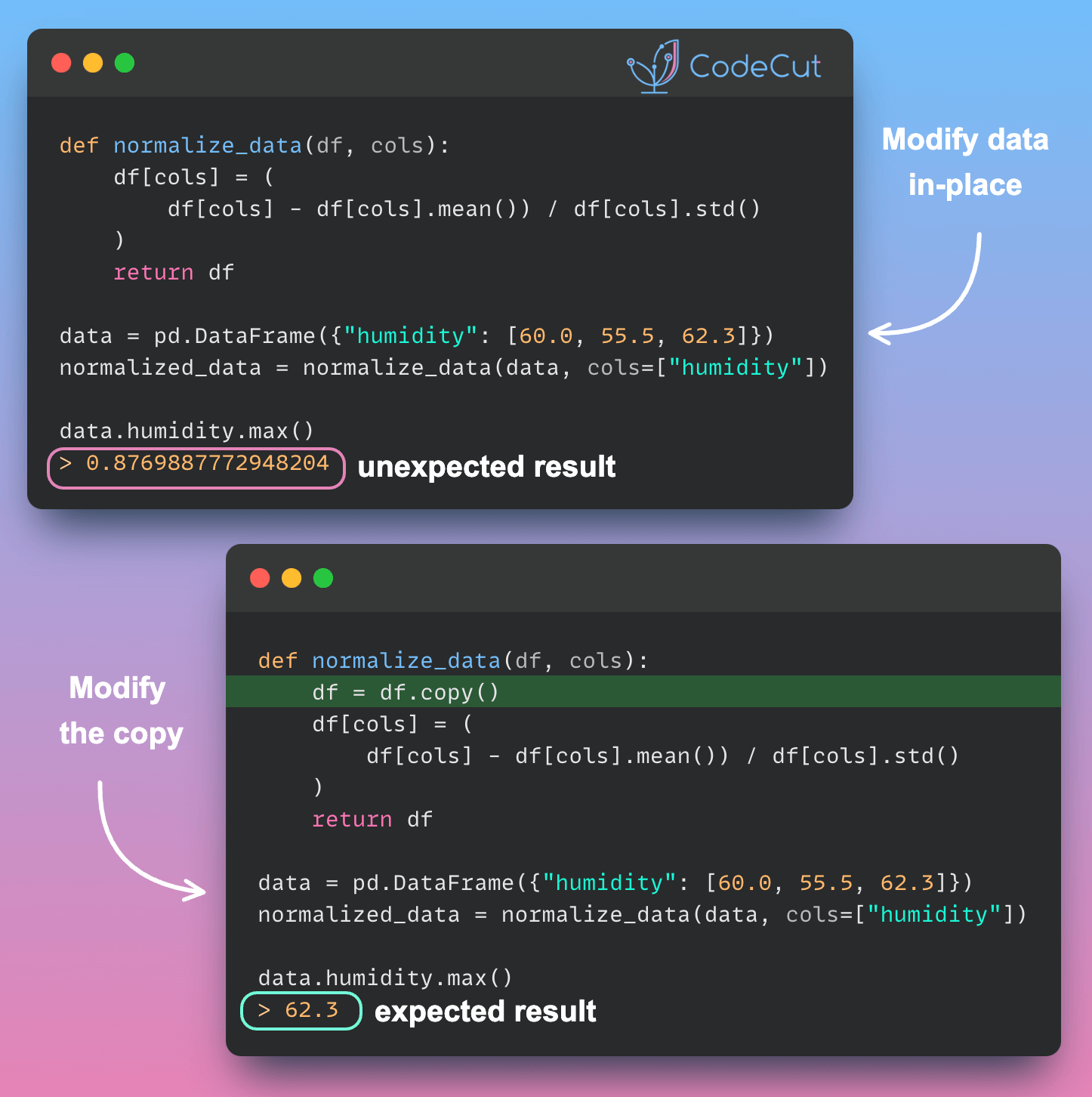
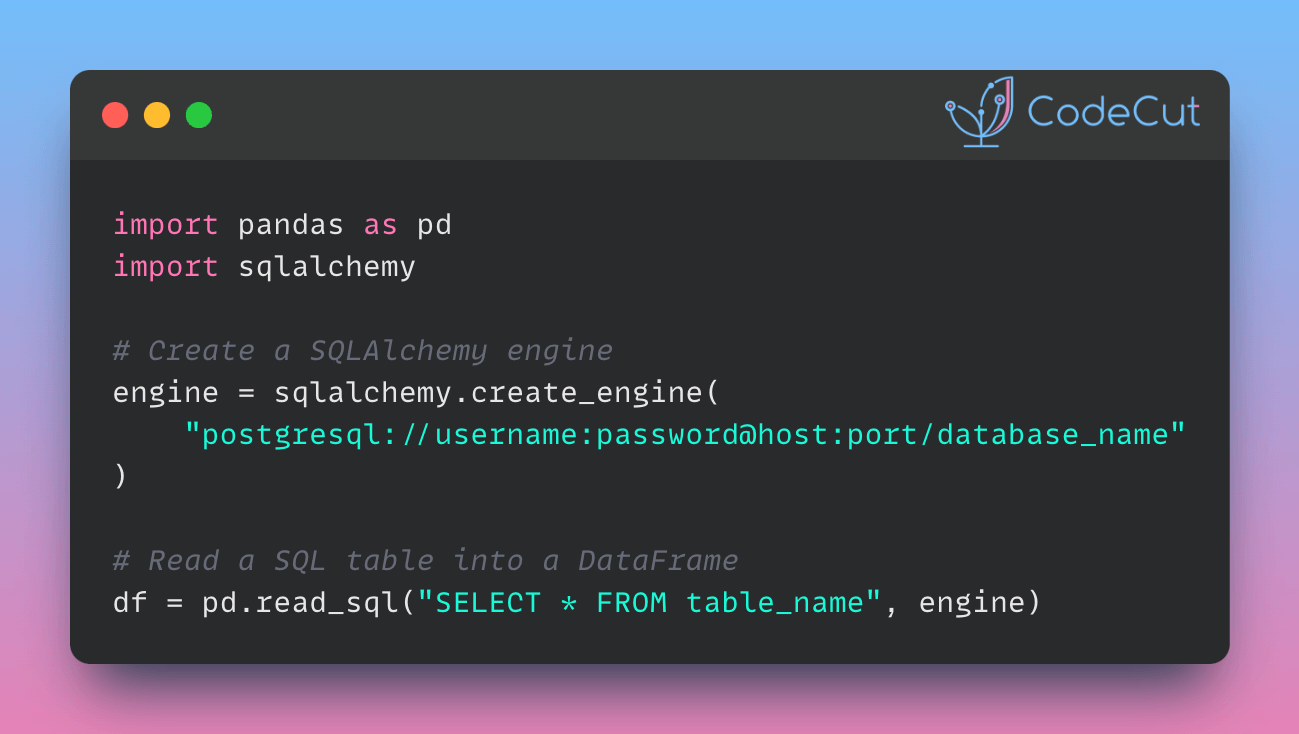
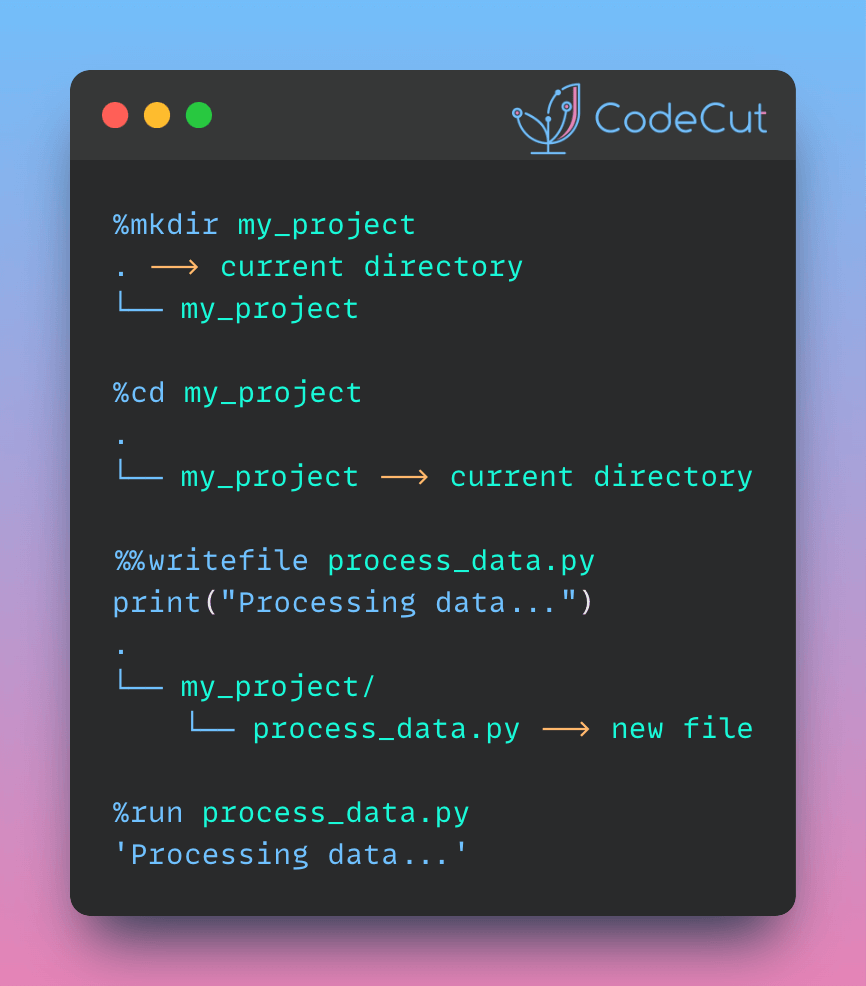
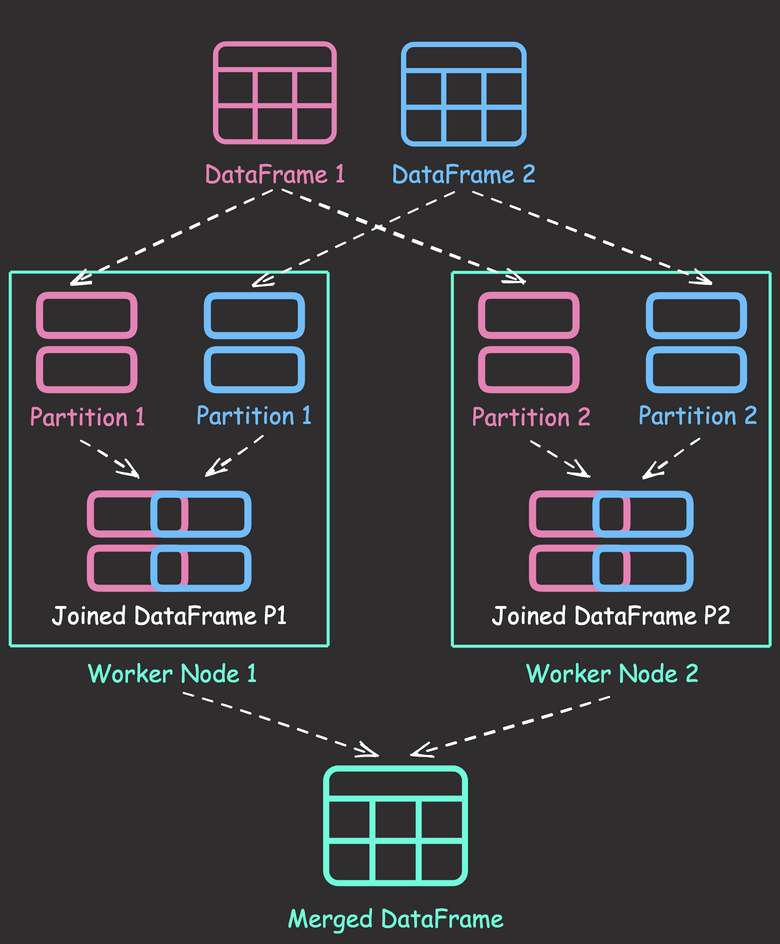
Data Analysis & ManipulationAnalyze DataManage DataFeature EngineerSQLMachine Learning & AIMachine LearningNatural Language ProcessingTime SeriesLLMCode QualityPython TipsPython-UtilitiesCode OptimizationDevOpsTestingGitCommand LineEnvironment ManagementBetter OutputsToolsNumPyPandasPolarsPySparkDelta LakeDuckDBJupyter NotebookVisualization & ReportingDashboardVisualizationWorkflow & AutomationWorkflow AutomationScrape DataX PySpark Best Practices: Simplifying Logical Chain Conditions November 9, 2024 Pin & Analyze: Better Jupyter Navigation with StickyLand October 29, 2024 Delta Lake vs Parquet: Preventing Data Loss During Write Operations October 27, 2024 Copy First, Modify Later: Ensuring Data Integrity in Pandas Operations October 22, 2024 Ensure Pandas’ Data Integrity with Delta Lake Constraints September 29, 2024 3 Powerful Ways to Create PySpark DataFrames September 13, 2024 From Python to Paper: Visualizing Calculations with LaTeX Handcalcs September 5, 2024 PySpark DataFrame Transformations: select vs withColumn September 2, 2024 How to Load SQL Tables into Pandas DataFrames August 28, 2024 Accelerating Complex Calculations: From Pandas to DuckDB August 22, 2024 From Complex SQL to Simple Merges: Delta Lake’s Upsert Solution August 20, 2024 Navigating and Managing Files in Notebooks: Top Magic Commands July 25, 2024 Pandas vs Polars: Syntax Comparison for Data Scientists July 23, 2024 Distributed Data Joining with Shuffle Joins in PySpark July 15, 2024 Enhance Code Modularity and Reusability with Temporary Views in PySpark July 8, 2024 « Previous Page1 Page2 Page3 Page4 Page5 Next »