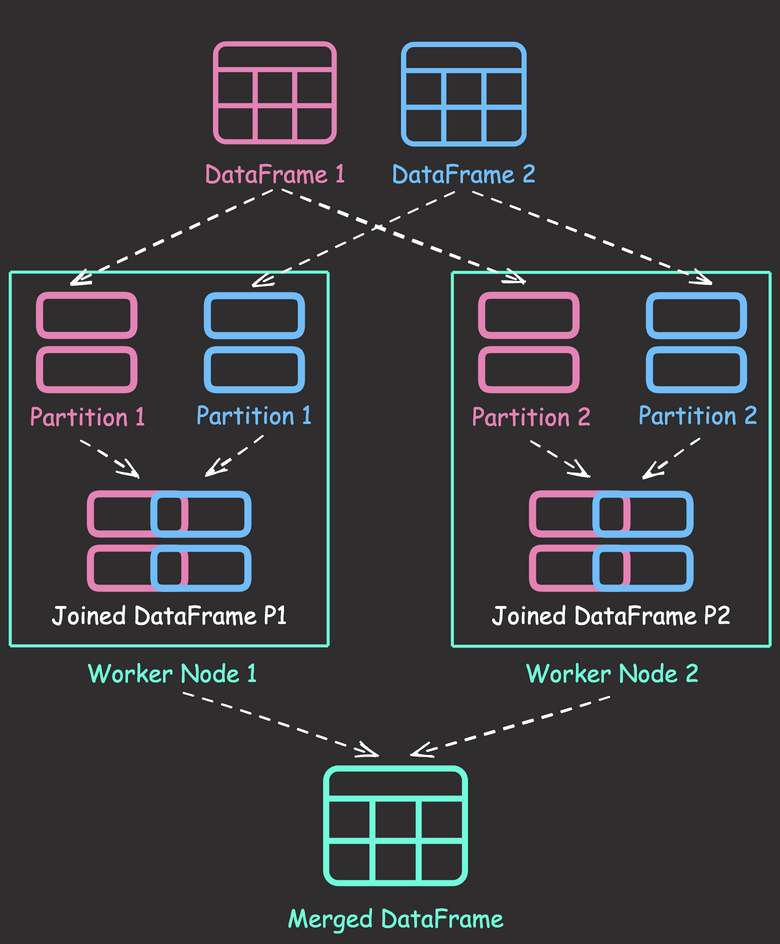

Shuffle joins in PySpark distribute data across worker nodes, enabling parallel processing and improving performance compared to single-node joins. By dividing data into partitions and joining each partition simultaneously, shuffle joins can handle large datasets efficiently.
Here’s an example of performing a shuffle join in PySpark:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
employees = spark.createDataFrame(
[(1, "John", "Sales"), (2, "Jane", "Marketing"), (3, "Bob", "Engineering")],
["id", "name", "department"],
)
salaries = spark.createDataFrame([(1, 5000), (2, 6000), (4, 7000)], ["id", "salary"])
# Perform an inner join using the join key "id"
joined_df = employees.join(salaries, "id", "inner")
joined_df.show()Output:
+---+----+----------+------+
| id|name|department|salary|
+---+----+----------+------+
| 1|John| Sales| 5000|
| 2|Jane| Marketing| 6000|
+---+----+----------+------+In this example, PySpark performs a shuffle join behind the scenes to combine the two DataFrames. The process involves partitioning the data based on the join key (“id”), shuffling the partitions across the worker nodes, performing local joins on each worker node, and finally merging the results.


