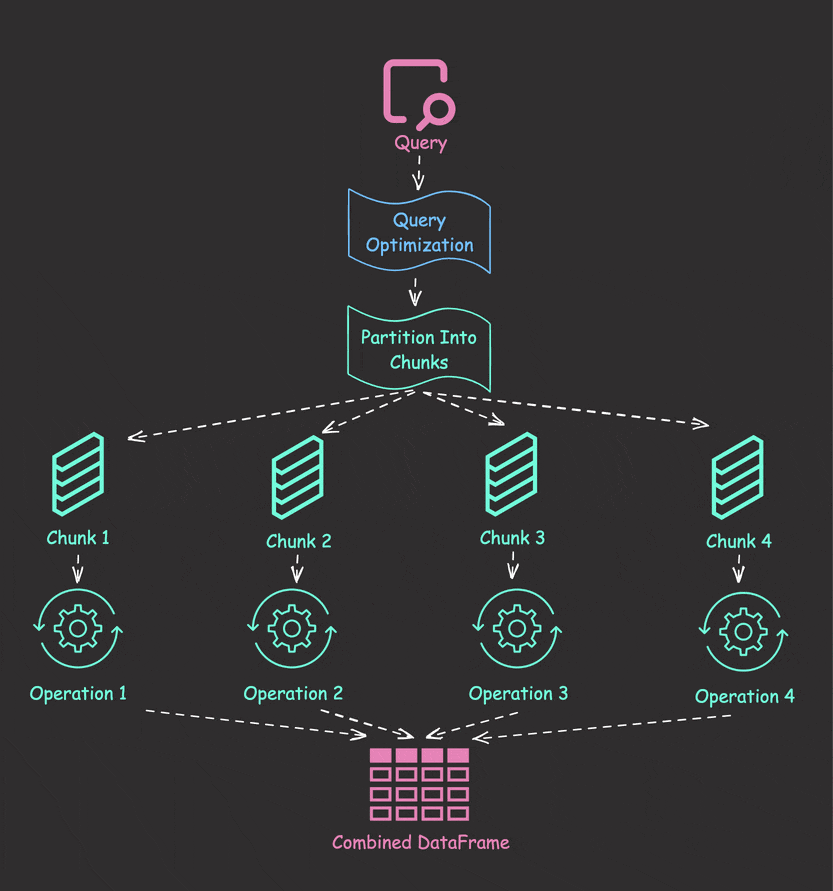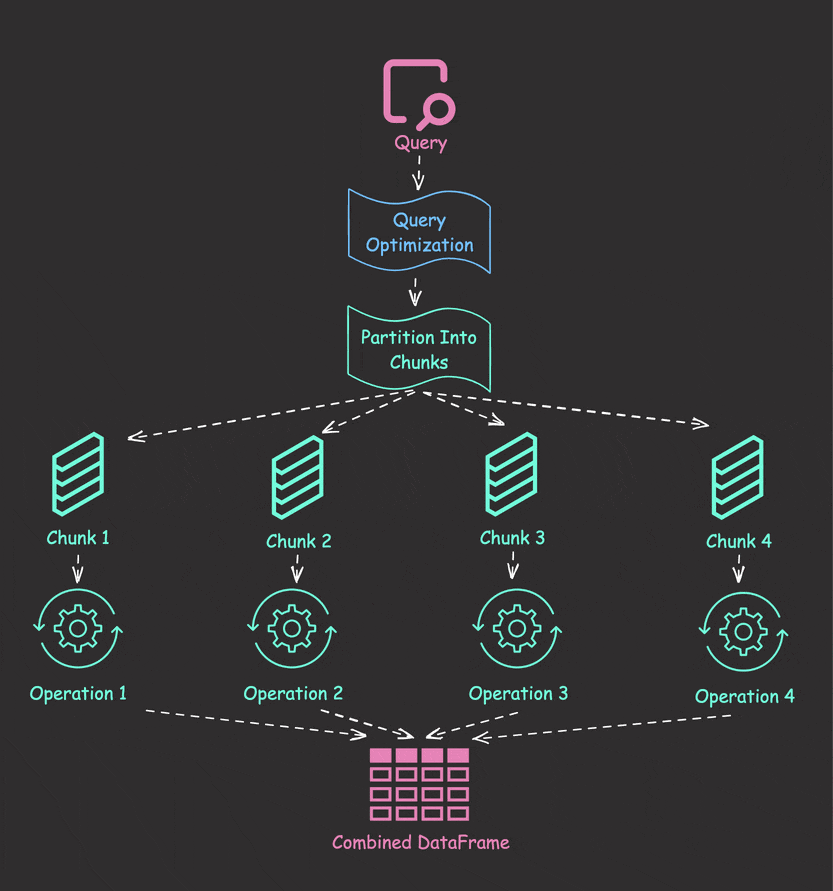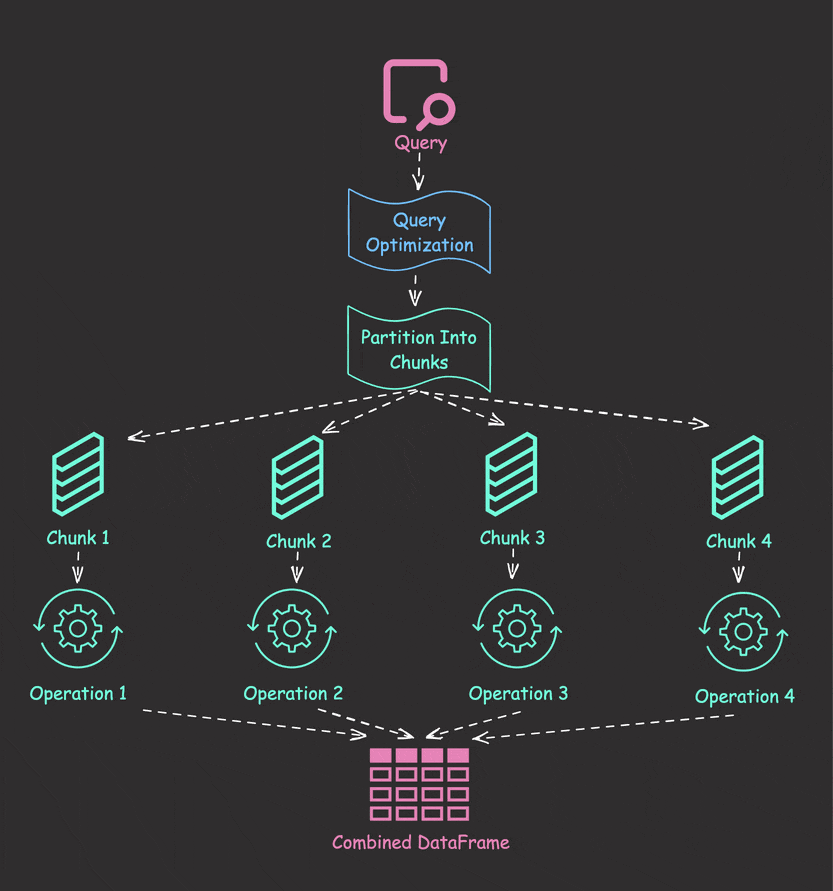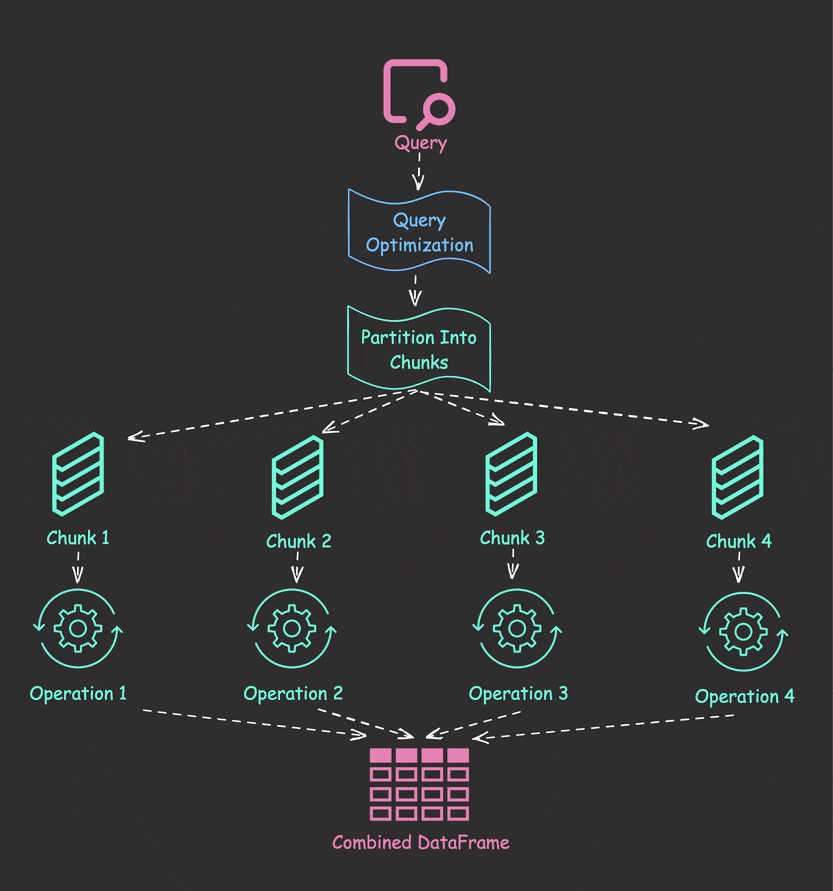
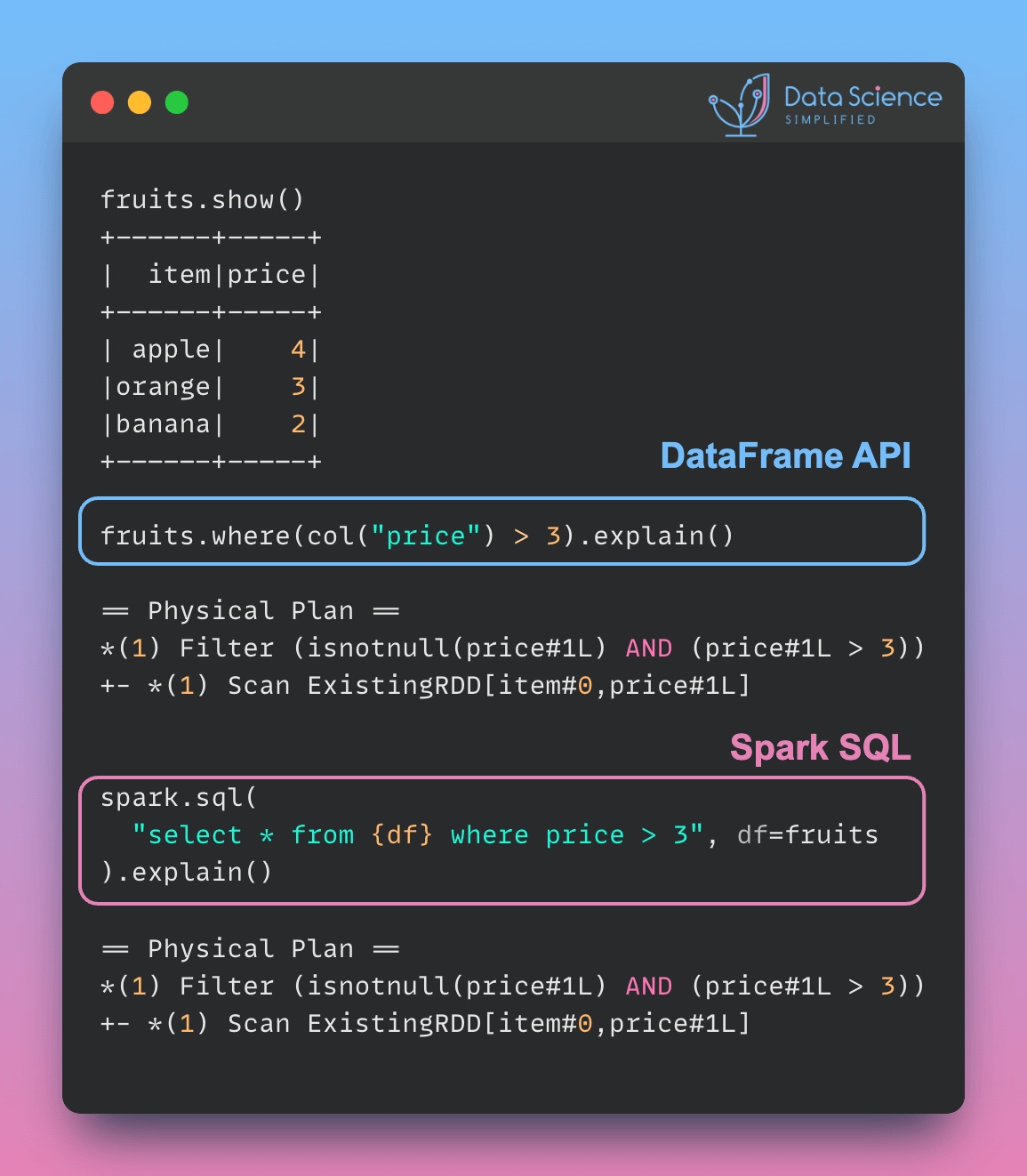
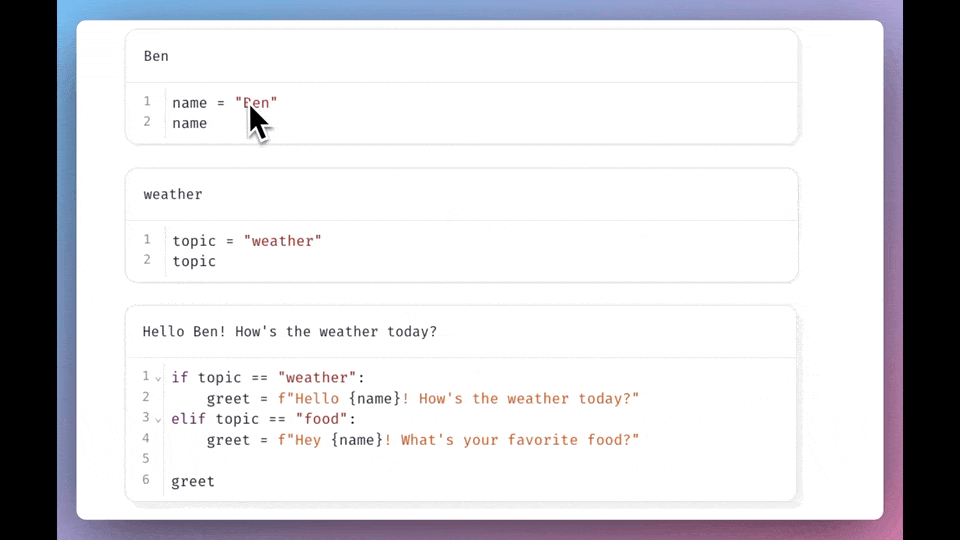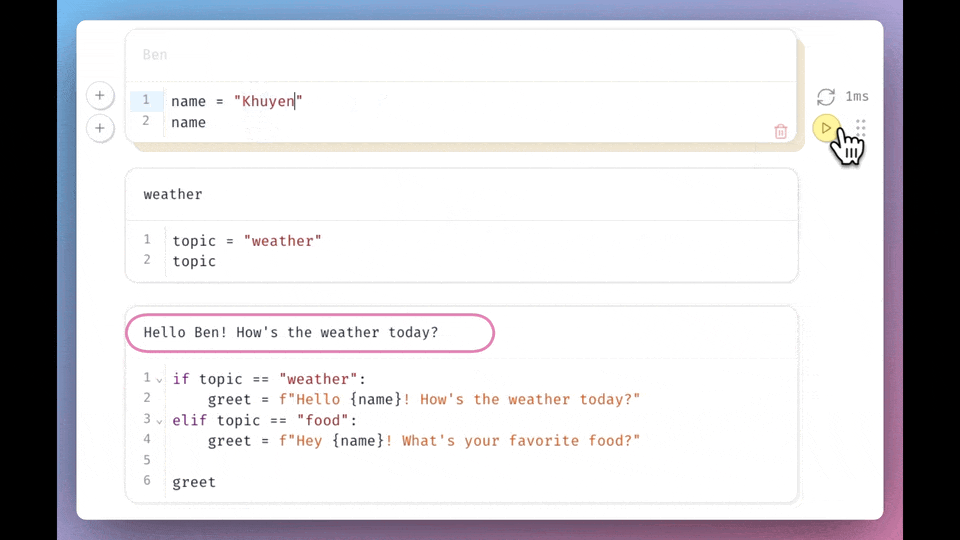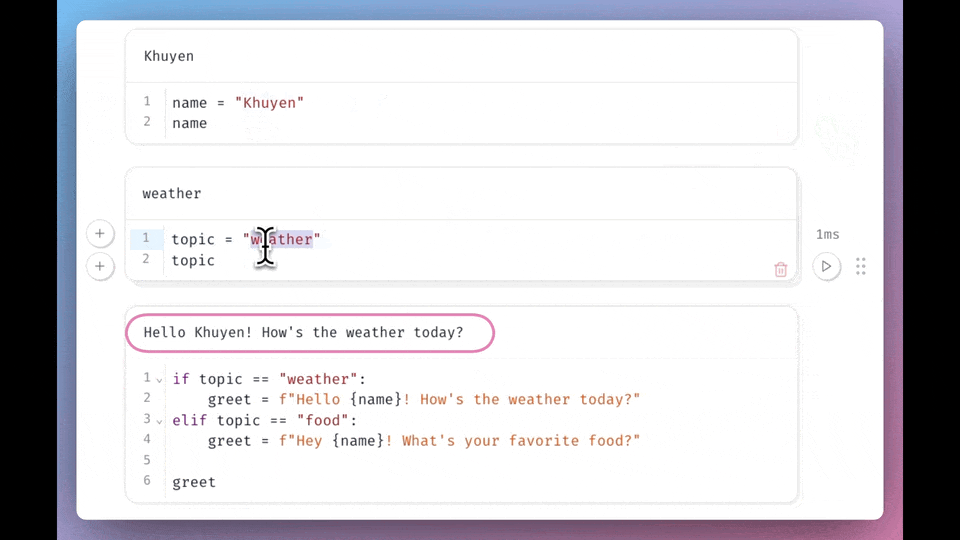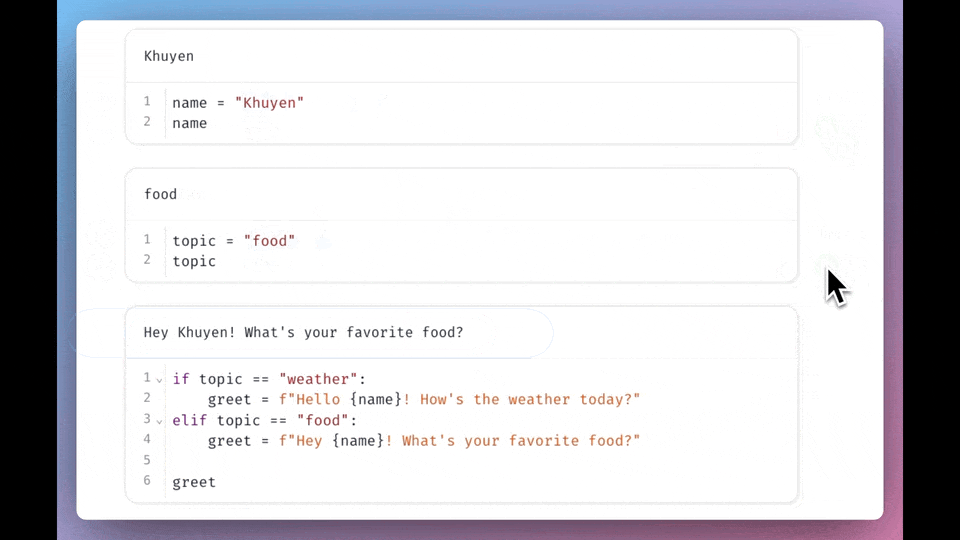
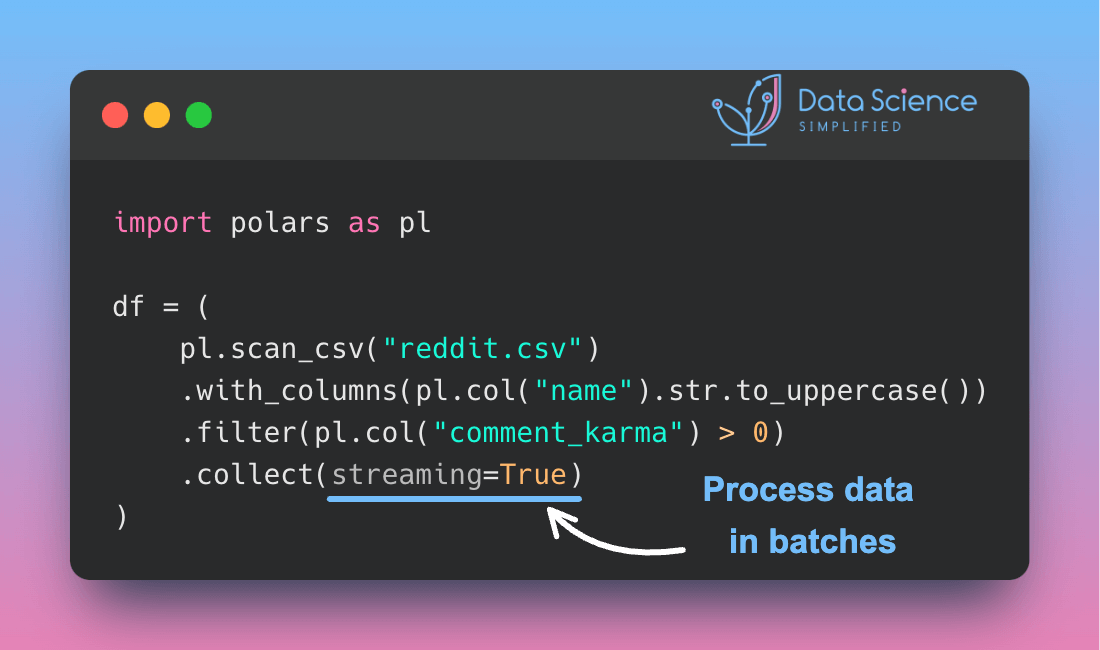
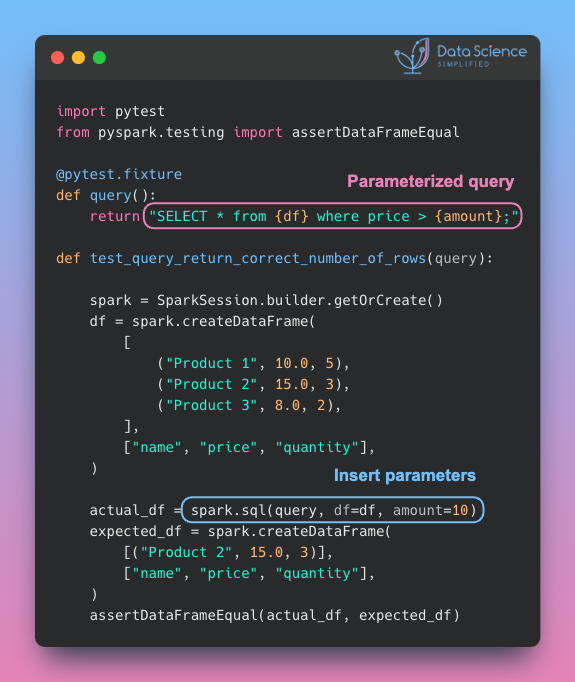
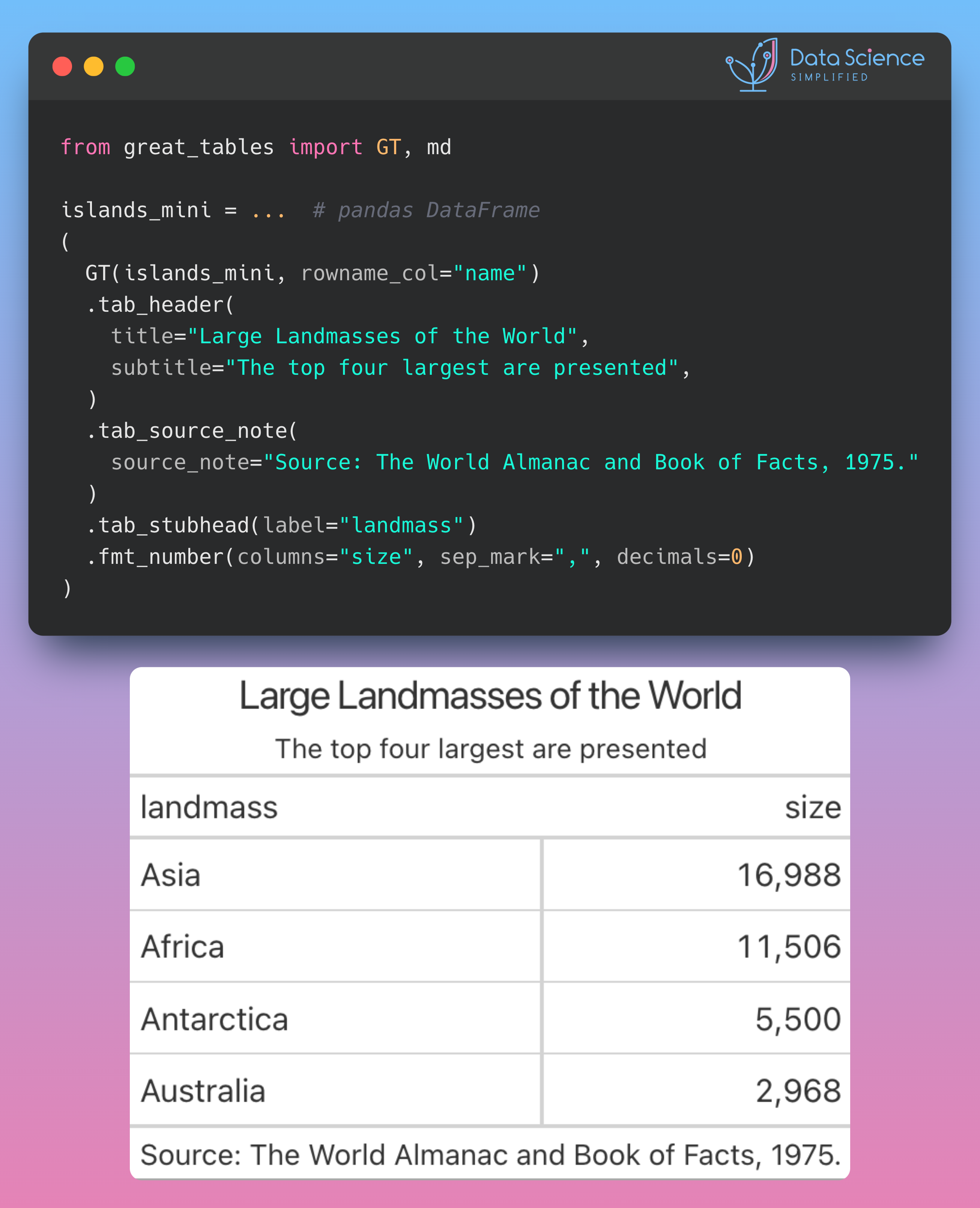
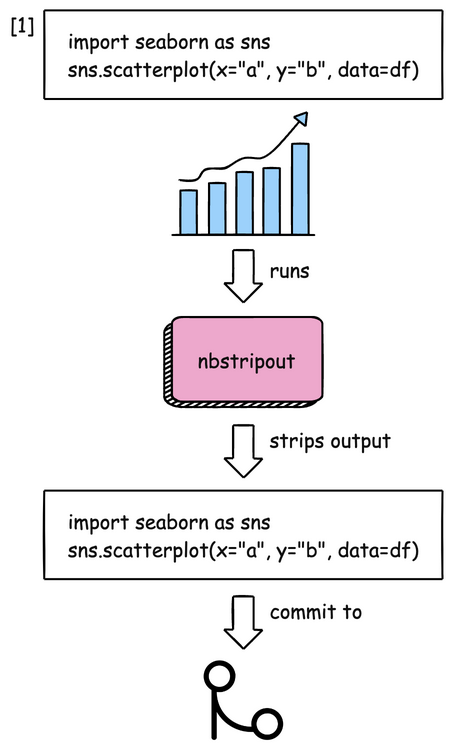
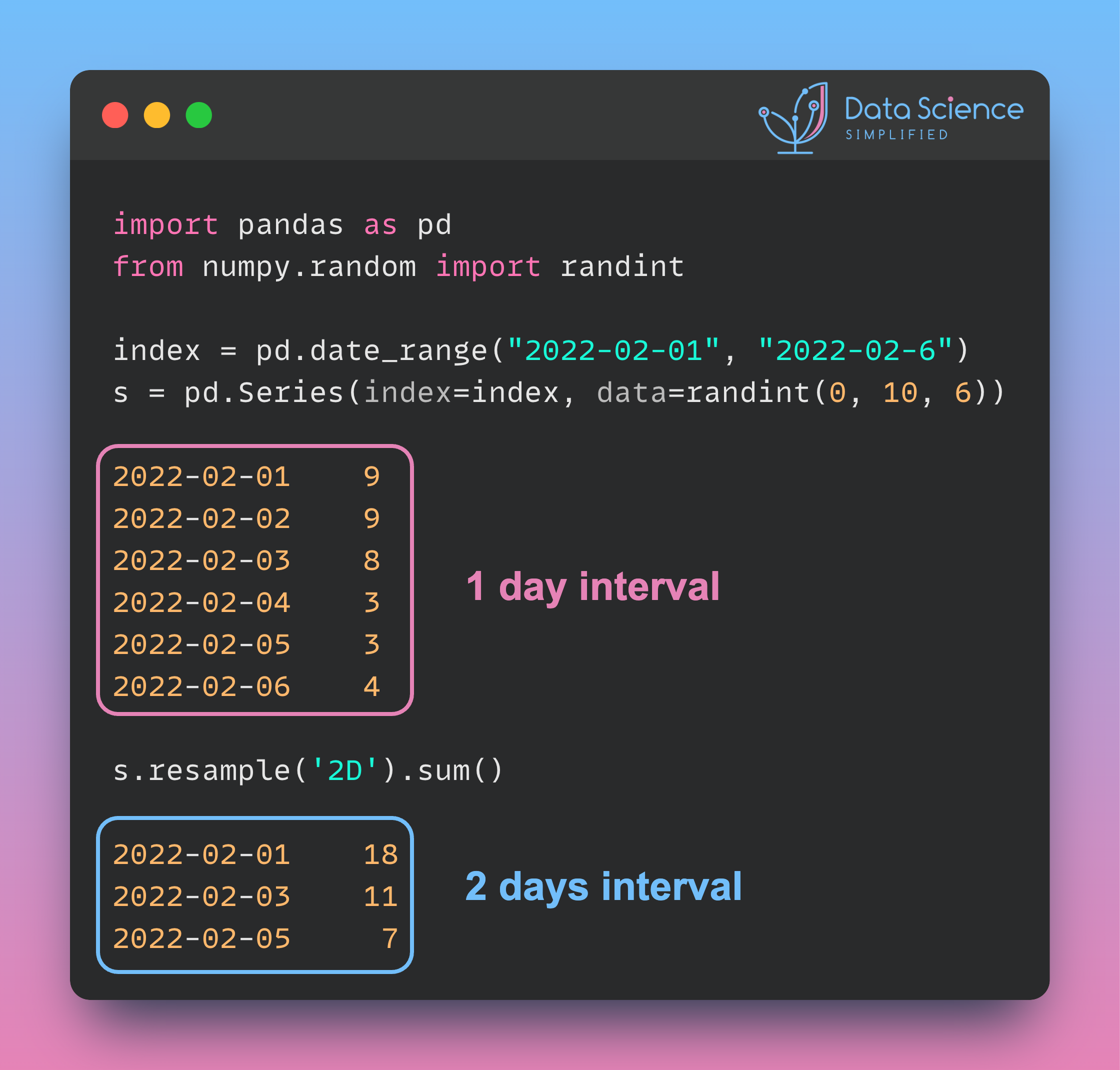
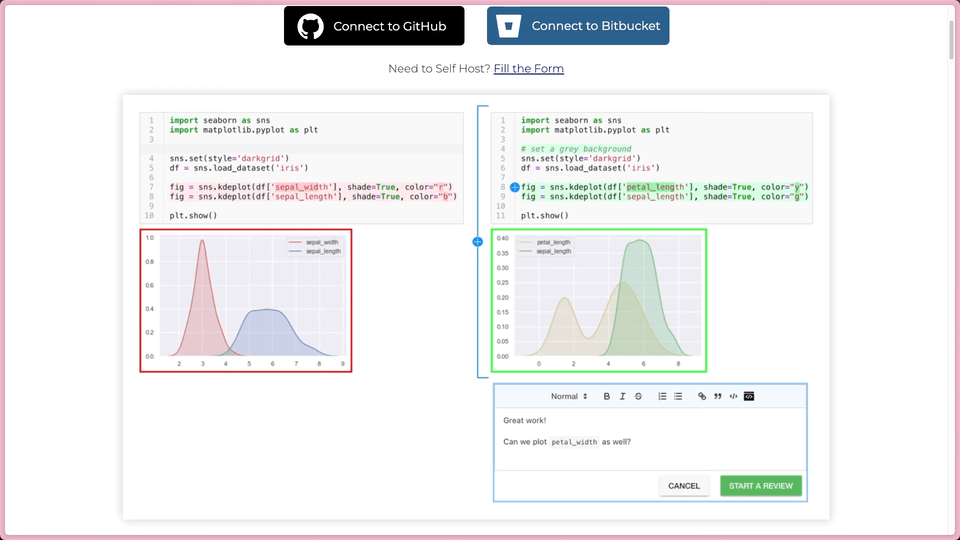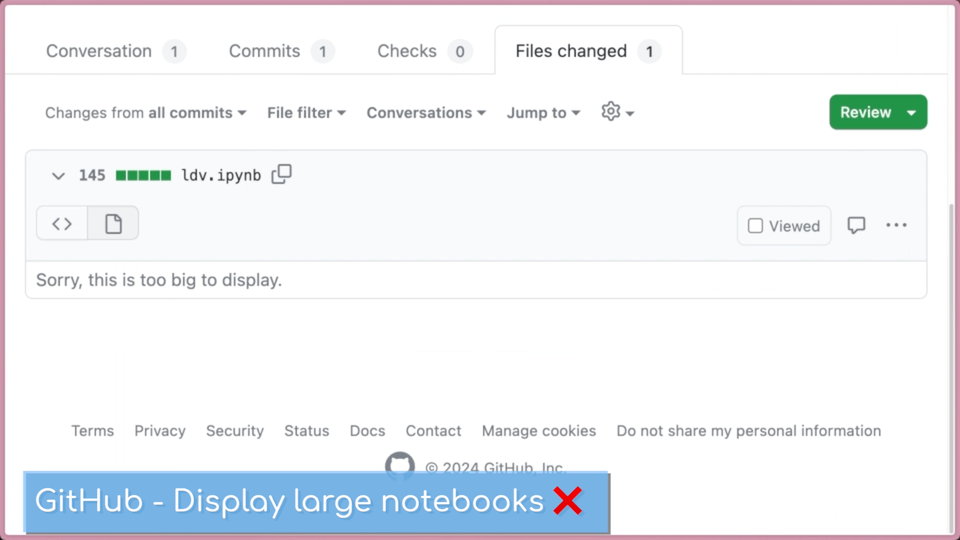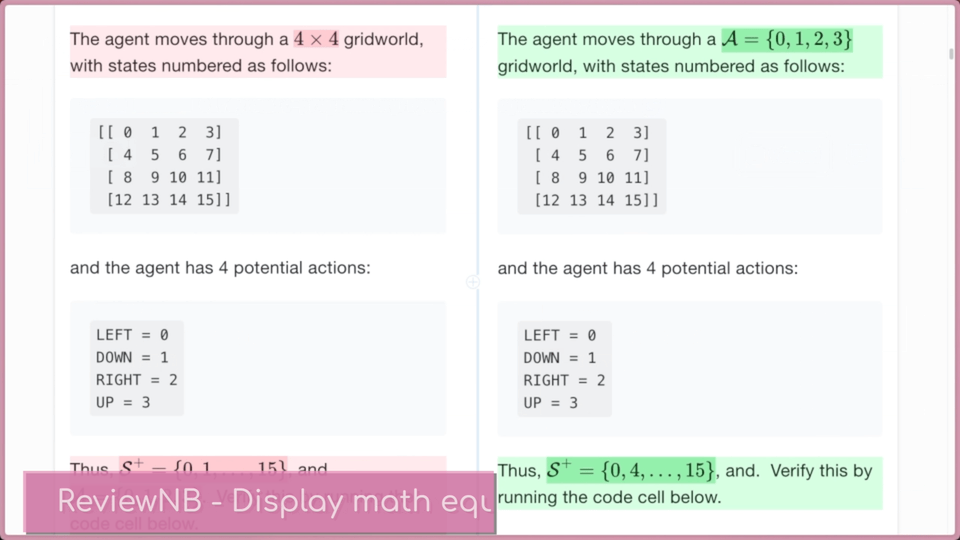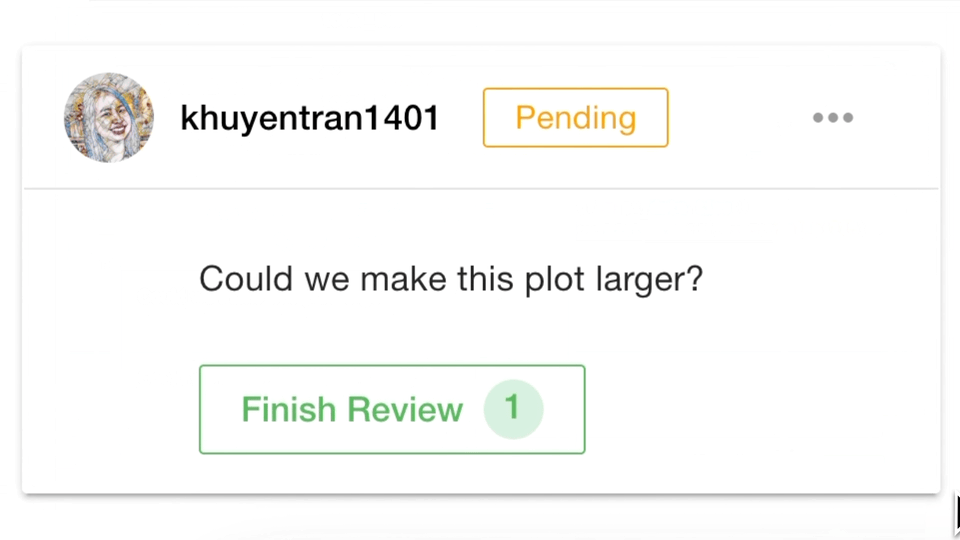
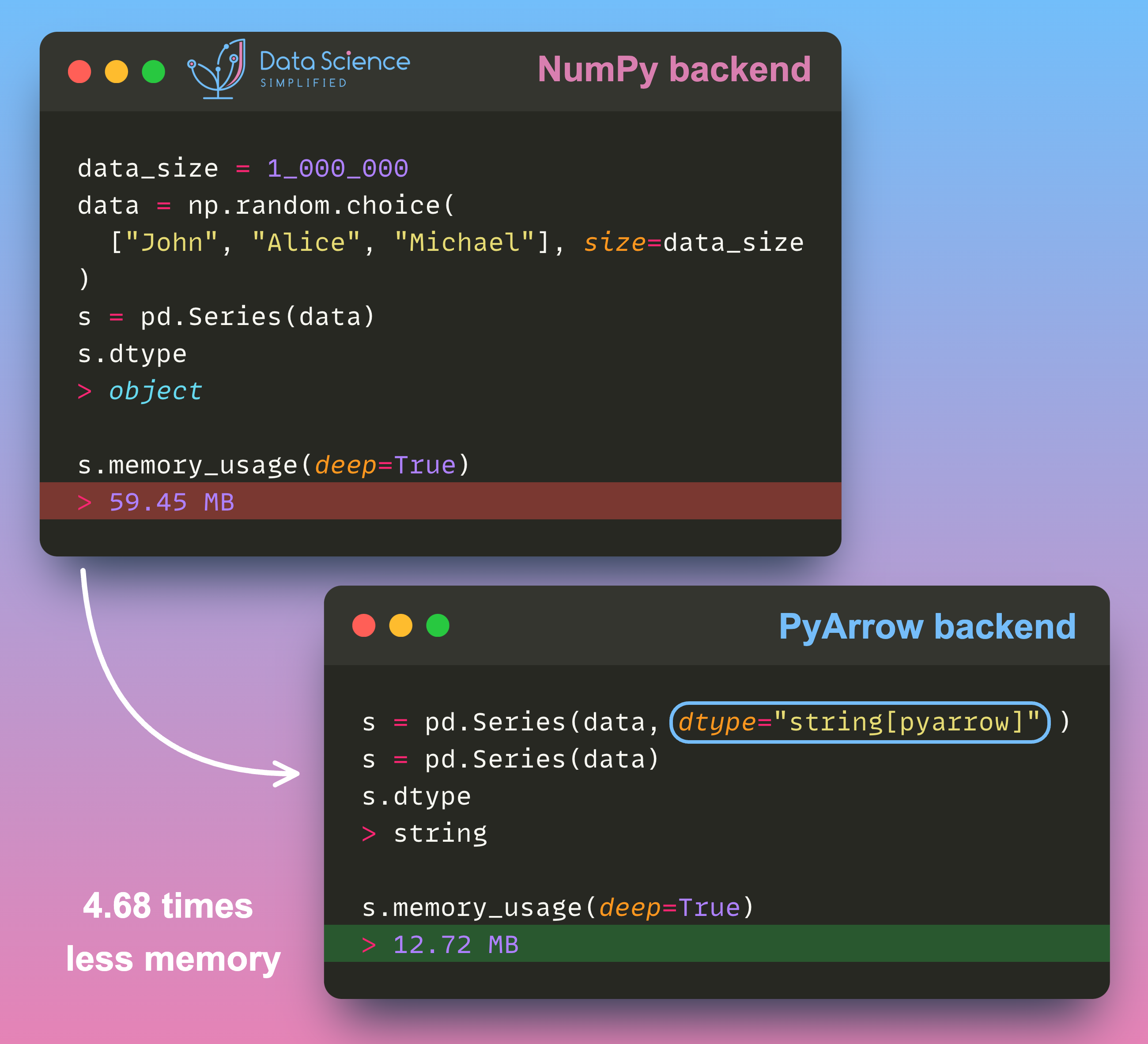
Data Analysis & ManipulationAnalyze DataManage DataFeature EngineerSQLMachine Learning & AIMachine LearningNatural Language ProcessingTime SeriesLLMCode QualityPython TipsPython-UtilitiesCode OptimizationDevOpsTestingGitCommand LineEnvironment ManagementBetter OutputsToolsNumPyPandasPolarsPySparkDelta LakeDuckDBJupyter NotebookVisualization & ReportingDashboardVisualizationWorkflow & AutomationWorkflow AutomationScrape DataX Polars: Write Queries Intuitively, Process Data Efficiently July 4, 2024 Pandas vs Polars: Harness Parallelism for Faster Data Processing June 27, 2024 Optimizing PySpark Queries: DataFrame API or SQL? June 24, 2024 marimo: The Solution for Reproducible and Consistent Notebooks June 21, 2024 Vectorized Operations in PySpark: pandas_udf vs Standard UDF June 10, 2024 Polars’ Streaming Mode: A Solution for Large Data Sets May 17, 2024 Simplify Unit Testing of SQL Queries with PySpark May 13, 2024 Great Tables: Create Scientific-Looking Tables in Python April 22, 2024 nbstripout: Efficiently Managing Notebook Outputs in Git April 12, 2024 Use Resample to Alter Time-Series Data Frequency April 4, 2024 Simplify Complex SQL Queries with PySpark UDFs April 1, 2024 Process Postgres Tables on Schedule with Kestra and Pandas March 14, 2024 Enhance Jupyter Notebook Collaboration on GitHub with ReviewNB March 13, 2024 Working with Arrays Made Easier in Spark 3.5 March 6, 2024 Efficient String Data Handling in pandas 2.0 with PyArrow Arrays March 5, 2024 « Previous Page1 Page2 Page3 Page4 Page5 Next »