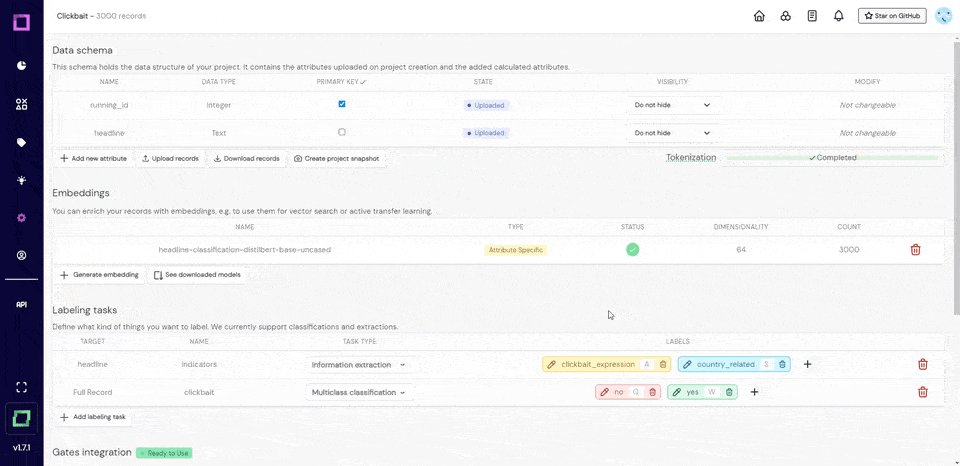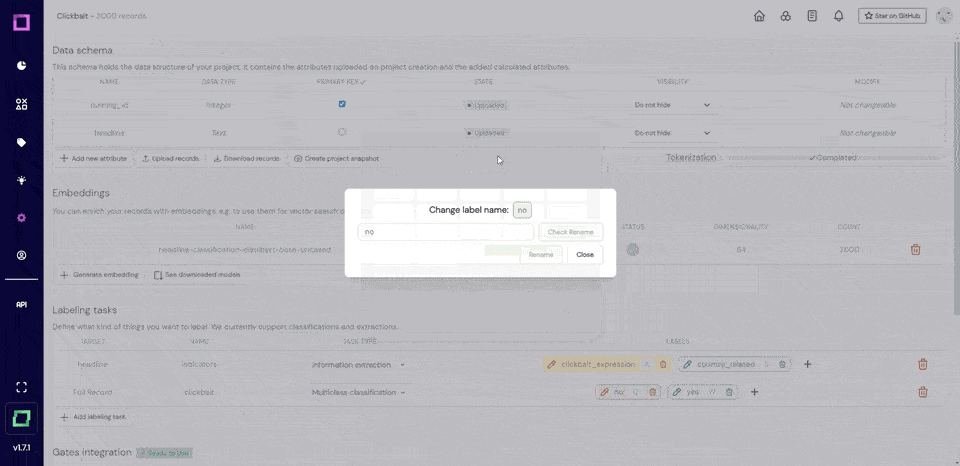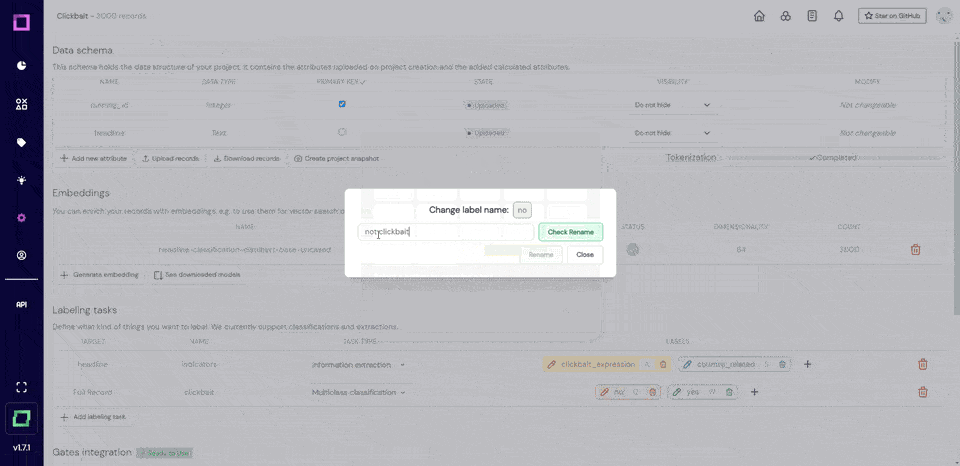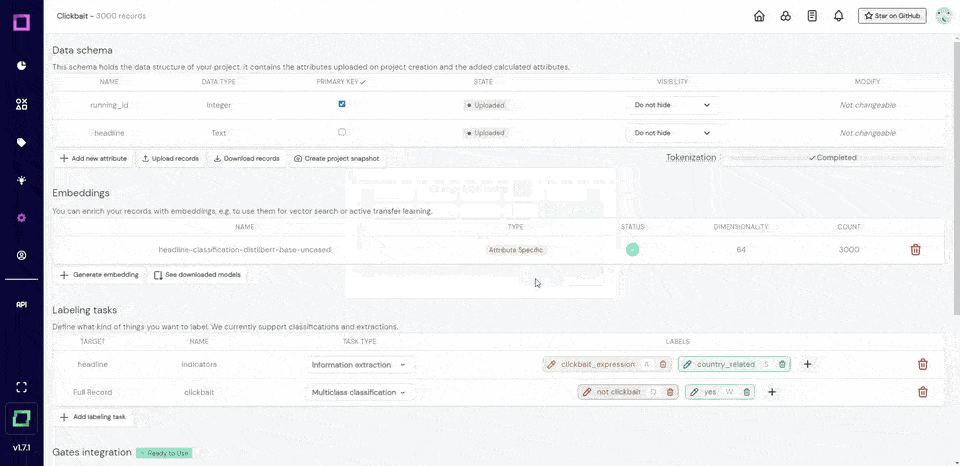

Handling text without proper word boundaries can be a significant challenge in data processing. Manual separation and pattern-based methods can be slow and complex.
Word Ninja uses probabilistic language models to quickly and accurately separate concatenated words.
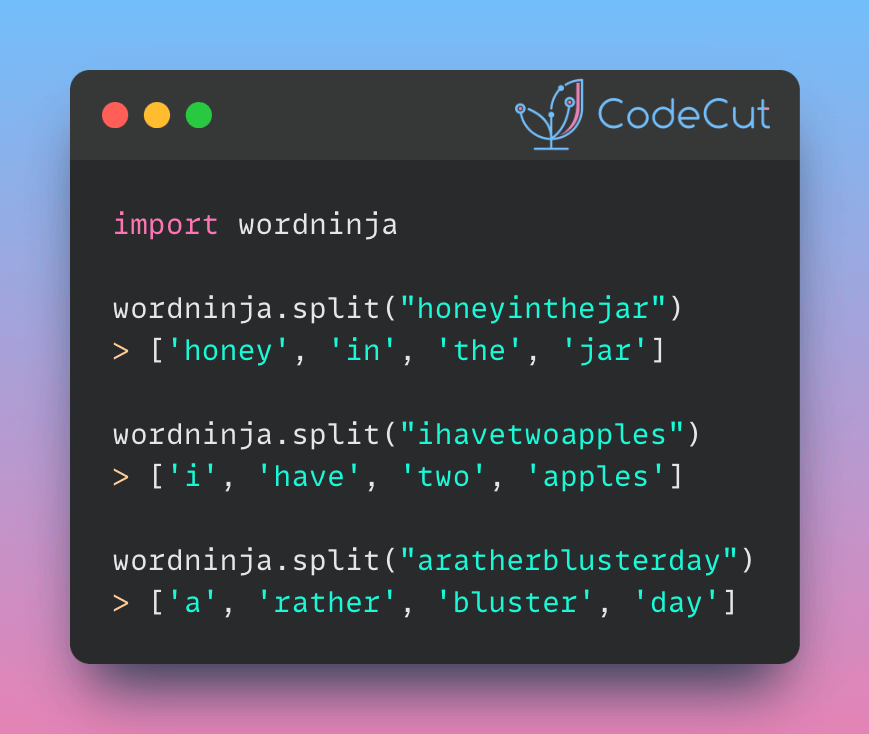
import wordninja
wordninja.split("honeyinthejar")
#> ['honey', 'in', 'the', 'jar']
wordninja.split("ihavetwoapples")
#> ['i', 'have', 'two', 'apples']
wordninja.split("aratherblusterday")
#> ['a', 'rather', 'bluster', 'day']