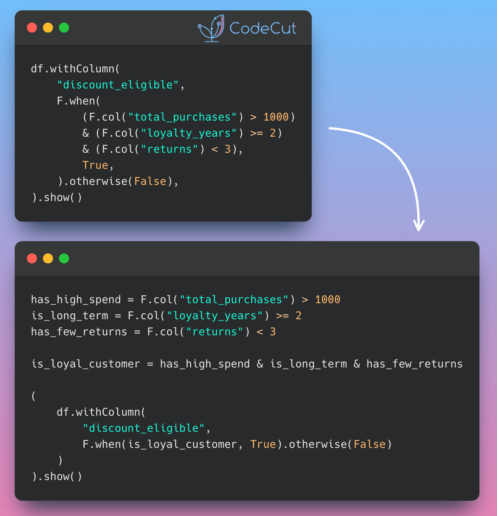
PySpark’s select and withColumn both can be used to add or modify existing columns. However, their behavior are different.
Let’s explore these differences with a practical example. First, let’s create a sample DataFrame:
from pyspark.sql.functions import col, upper
data = [
("Alice", 28, "New York"),
("Bob", 35, "San Francisco"),
]
df = spark.createDataFrame(data, ["name", "age", "city"])
df.show()Output:
+-----+---+-------------+
| name|age| city|
+-----+---+-------------+
|Alice| 28| New York|
| Bob| 35|San Francisco|
+-----+---+-------------+Using Select
select keeps only the specified columns:
df_select = df.select("name", upper(col("city")).alias("upper_city"))
df_select.show()Output:
+-------+-------------+
| name| upper_city|
+-------+-------------+
| Alice| NEW YORK|
| Bob|SAN FRANCISCO|
|Charlie| LOS ANGELES|
| Diana| CHICAGO|
+-------+-------------+Using withColumn
withColumn retains all original columns plus the new/modified one:
df_withColumn = df.withColumn('upper_city', upper(col('city')))
df_withColumn.show()Output:
+-------+---+-------------+-------------+
| name|age| city| upper_city|
+-------+---+-------------+-------------+
| Alice| 28| New York| NEW YORK|
| Bob| 35|San Francisco|SAN FRANCISCO|
|Charlie| 42| Los Angeles| LOS ANGELES|
| Diana| 31| Chicago| CHICAGO|
+-------+---+-------------+-------------+Key Takeaway
- Use
selectfor column subset selection or major DataFrame reshaping. - Use
withColumnfor incremental column additions or modifications.