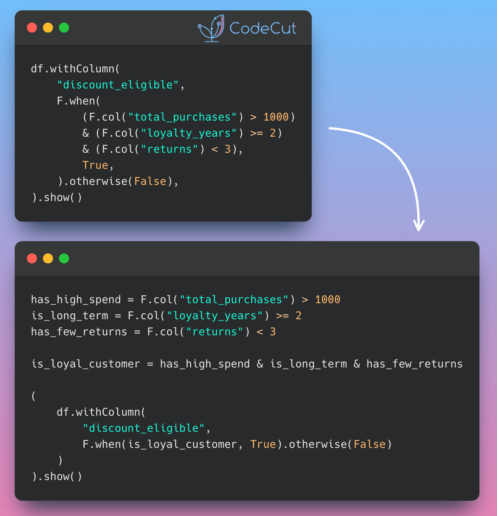
As data scientists and engineers working with big data, we often rely on PySpark for its distributed computing capabilities. One of the fundamental tasks in PySpark is creating DataFrames. Let’s explore three powerful methods to accomplish this, each with its own advantages.
1. Using StructType and StructField
This method gives you explicit control over your data schema:
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
data = [("Alice", 25), ("Bob", 30), ("Charlie", 35)]
schema = StructType([
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)
])
df = spark.createDataFrame(data, schema)Key benefits:
- Explicit schema control
- Early-type mismatch detection
- Optimized performance
This approach is ideal when you need strict control over data types and structure.
2. Using Row Objects
For a more Pythonic approach, consider using Row objects:
from pyspark.sql import Row
data = [Row(name="Alice", age=25), Row(name="Bob", age=30), Row(name="Charlie", age=35)]
df = spark.createDataFrame(data)Key benefits:
- Pythonic approach
- Flexible for evolving data structures
This method shines when your data structure might change over time.
3. From Pandas DataFrame
If you’re coming from a Pandas background, this method will feel familiar:
import pandas as pd
pandas_df = pd.DataFrame({"name": ["Alice", "Bob", "Charlie"], "age": [25, 30, 35]})
df = spark.createDataFrame(pandas_df)Key benefits:
- Seamless integration with Pandas workflows
- Familiar to data scientists
This is particularly useful when transitioning from Pandas to PySpark.
The Result
Regardless of the method you choose, all three approaches produce the same result:
+-------+---+
| name|age|
+-------+---+
| Alice| 25|
| Bob| 30|
|Charlie| 35|
+-------+---+