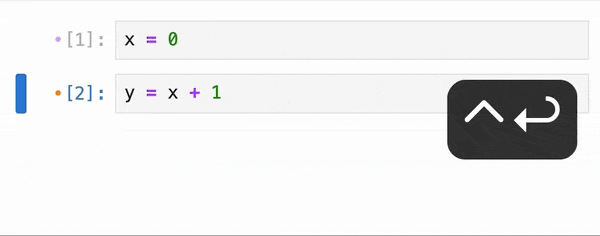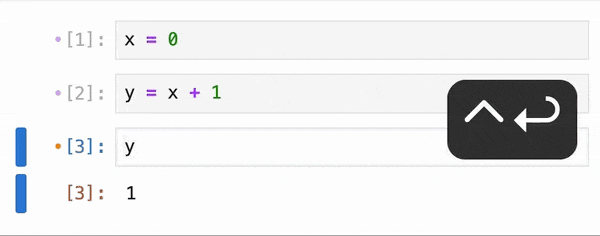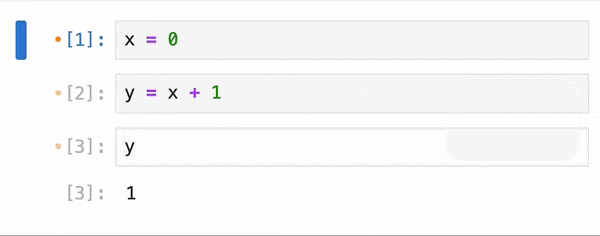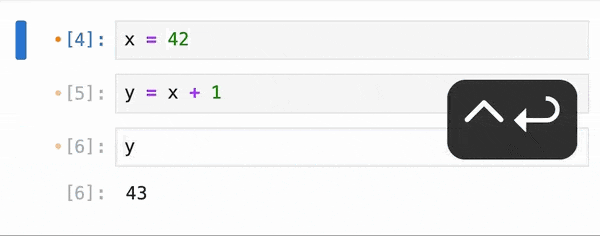
When it comes to data processing, the execution approach can significantly impact performance. Pandas, a popular data manipulation library in Python, uses eager execution by default. This means that operations are carried out in the order they are written, processing data immediately and loading everything into memory at once. While this approach can be straightforward, it can lead to slow computations and high memory usage when dealing with large datasets.
On the other hand, Polars, a modern in-memory data processing library, offers both eager and lazy execution modes. In lazy execution mode, a query optimizer evaluates all required operations and maps out the most efficient way to execute the code. This can include rewriting the execution order of operations or dropping redundant calculations.
Example: Grouping and Aggregating a Large Dataset
Let’s consider an example where we have a large dataset with 10 million rows, and we want to group the data by region, calculate the sum of revenue and count of orders, and filter the results to only include the North and South regions.
Eager Execution with Pandas
With eager execution, Pandas will:
- Execute operations immediately, loading all data into memory
- Keep intermediate results in memory during each step
- Execute operations in the exact order written
import numpy as np
import pandas as pd
# Generate sample data
N = 10_000_000
data = {
"region": np.random.choice(["North", "South", "East", "West"], N),
"revenue": np.random.uniform(100, 10000, N),
"orders": np.random.randint(1, 100, N),
}
def analyze_sales_pandas(df):
# Loads and processes everything in memory
return (
df.groupby("region")
.agg({"revenue": "sum"})
.loc[["North", "South"]]
)
pd_df = pd.DataFrame(data)
%timeit analyze_sales_pandas(pd_df)
Output:
367 ms ± 47 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)As you can see, the eager execution approach takes approximately 366 milliseconds to complete.
Lazy Execution with Polars
With lazy execution, Polars will:
- Create an execution plan first, optimizing the entire chain before processing any data
- Only process data once at .collect(), reducing memory overhead
- Rearrange operations for optimal performance (pushing filters before groupby)
import polars as pl
def analyze_sales_polars(df):
# Creates execution plan, no data processed yet
result = (
df.lazy()
.group_by("region")
.agg(pl.col("revenue").sum())
.filter(pl.col("region").is_in(["North", "South"]))
.collect() # Only now data is processed
)
return result
pl_df = pl.DataFrame(data)
%timeit analyze_sales_polars(pl_df)
Output:
170 ms ± 15.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)As we can see, the lazy execution approach with Polars takes approximately 211 milliseconds to complete, which is about 53.68% faster than the eager execution approach with Pandas.


Conclusion
In conclusion, the execution approach can significantly impact performance when processing large datasets. While Pandas’ eager execution approach can be straightforward, it can lead to slow computations and high memory usage. Polars’ lazy execution mode, on the other hand, offers a more efficient way to execute code by optimizing the entire chain of operations before processing any data.
By using lazy execution with Polars, you can achieve faster execution and lower memory usage compared to Pandas’ eager execution approach.