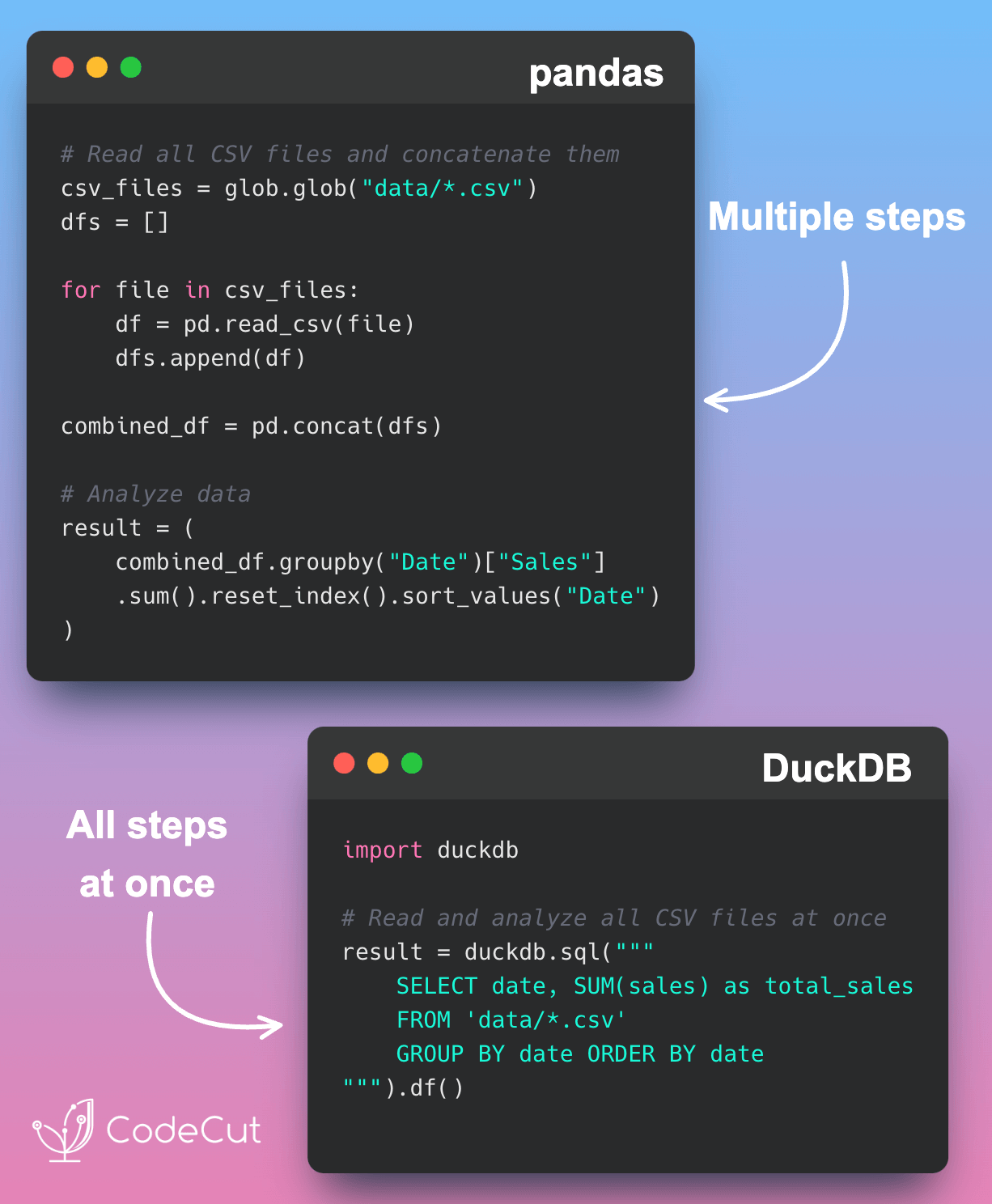
Motivation
Reading CSV files without specifying delimiters, headers, or data types can lead to incorrect parsing, especially when dealing with custom delimiters or unique formatting. For example, using Pandas without specifying these parameters can result in treating entire rows as a single column.
Consider the following example:
import pandas as pd
# Example CSV content with a custom delimiter
csv_content = """FlightDate|UniqueCarrier|OriginCityName|DestCityName
1988-01-01|AA|New York, NY|Los Angeles, CA
1988-01-02|AA|New York, NY|Los Angeles, CA
1988-01-03|AA|New York, NY|Los Angeles, CA
"""
# Writing the CSV content to a file
with open("example.csv", "w") as f:
f.write(csv_content)
# Reading the CSV file with pandas without specifying the delimiter
df = pd.read_csv("example.csv")
print(df)
Output:
FlightDate|UniqueCarrier|OriginCityName|DestCityName
1988-01-01|AA|New York NY|Los Angeles CA
1988-01-02|AA|New York NY|Los Angeles CA
1988-01-03|AA|New York NY|Los Angeles CA In this scenario, Pandas assumes the default delimiter (,) and incorrectly parses the data, resulting in a dataframe where each row is treated as a single column.
Introduction to DuckDB
DuckDB is a high-performance, in-process SQL database management system designed for analytical workloads. It is lightweight, fast, and supports seamless integration with Python, R, and other programming environments. DuckDB provides advanced SQL capabilities, including automatic CSV parsing, eliminating the need to manually specify delimiters, headers, or data types.
To install DuckDB, simply run:
pip install duckdb
DuckDB’s read_csv function simplifies CSV parsing by automatically detecting the file’s structure. It has been previously discussed in articles such as Simplify CSV Data Management with DuckDB and Streamline Pattern-Based CSV Processing with DuckDB SQL. These articles highlighted how DuckDB simplifies CSV management and efficiently processes multiple files.
In this post, we will focus on using the read_csv method to automate CSV parsing.
read_csv
DuckDB’s read_csv feature automatically detects delimiters, headers, and column types, ensuring accurate parsing of CSV files. Here’s how it works:
import duckdb
# Use DuckDB to automatically detect and read the CSV structure
result = duckdb.query("SELECT * FROM read_csv('example.csv')").to_df()
print(result)Output:
FlightDate UniqueCarrier OriginCityName DestCityName
0 1988-01-01 AA New York, NY Los Angeles, CA
1 1988-01-02 AA New York, NY Los Angeles, CA
2 1988-01-03 AA New York, NY Los Angeles, CAIn this example:
- The
read_csvfunction automatically detects the pipe (|) delimiter. - It identifies the column headers and infers the correct data types.
- The
duckdb.querymethod runs the SQL query, and.to_df()converts the result into a pandas DataFrame.
Output:
FlightDate UniqueCarrier OriginCityName DestCityName
0 1988-01-01 AA New York, NY Los Angeles, CA
1 1988-01-02 AA New York, NY Los Angeles, CA
2 1988-01-03 AA New York, NY Los Angeles, CADuckDB successfully detects the delimiter and correctly parses the data into columns without requiring any manual configuration.
Conclusion
DuckDB’s read_csv feature simplifies CSV parsing by automatically detecting file structures and enabling efficient SQL-based operations.
For more information, check out the articles Simplify CSV Data Management with DuckDB and Streamline Pattern-Based CSV Processing with DuckDB SQL.