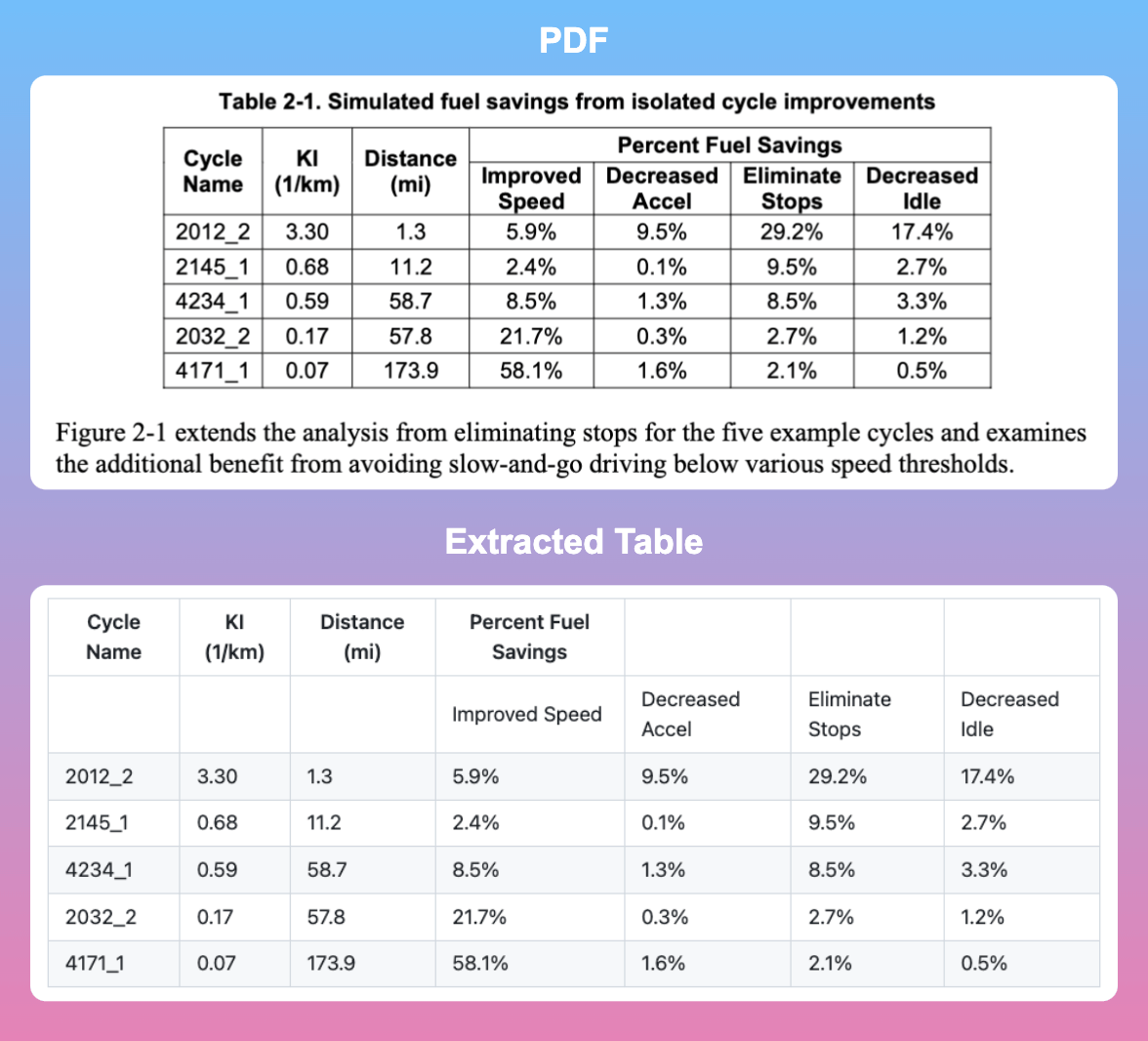

With Camelot, you can extract tables from PDFs using Python and convert the data into a more structured format, such as a pandas DataFrame or a CSV file for efficient analysis, manipulation, and integration.
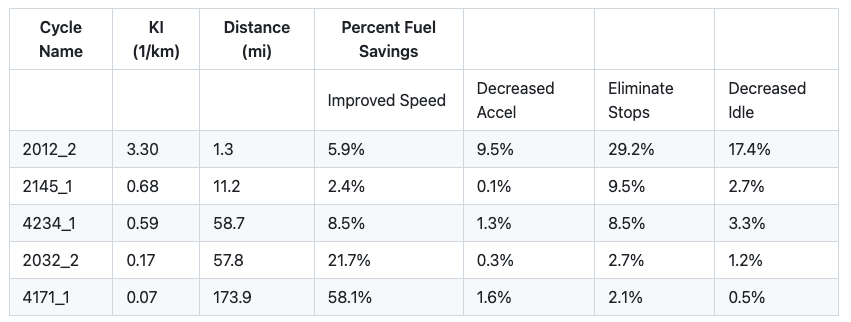
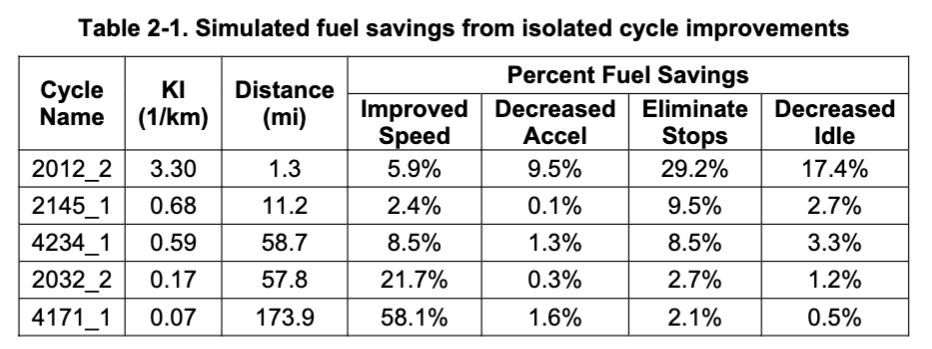
To see how Camelot works, start by reading the PDF file named ‘foo.pdf’ that contains the following table:
import camelot
tables = camelot.read_pdf('foo.pdf')
tablesThe output shows that there is one table extracted from the PDF file.
Export the extracted tables to a CSV file named ‘foo.csv’. Camelot also supports exporting tables to other formats like JSON, Excel, HTML, Markdown, and SQLite databases.
tables[0].parsing_report
{
'accuracy': 99.02,
'whitespace': 12.24,
'order': 1,
'page': 1
}
tables[0].to_csv('foo.csv') # to_json, to_excel, to_html, to_markdown, to_sqlite
tables[0].df # get a pandas DataFrame!