Skip to content
Daily Tips
Blog
Book
Sponsor
Account
Login
contact me
Daily Tips
Blog
Book
Sponsor
Account
Login
contact me
Search
Data Analysis & Manipulation
Analyze Data
Manage Data
NumPy
Pandas
Pandas Alternatives
PySpark
SQL
Development & Coding
Code Optimization
Python Tips
Python Utilities
Testing
Machine Learning & AI
Feature Engineer
LLM
Machine Learning
Natural Language Processing
Time Series
Tools & Environments
Command Line
Environment Management
Git
Jupyter Notebook
Visualization & Reporting
Dashboard
Visualization
Workflow & Automation
Better Outputs
Workflow Automation
Data Analysis & Manipulation
Analyze Data
Manage Data
NumPy
Pandas
Pandas Alternatives
PySpark
SQL
Development & Coding
Code Optimization
Python Tips
Python Utilities
Testing
Machine Learning & AI
Feature Engineer
LLM
Machine Learning
Natural Language Processing
Time Series
Tools & Environments
Command Line
Environment Management
Git
Jupyter Notebook
Visualization & Reporting
Dashboard
Visualization
Workflow & Automation
Better Outputs
Workflow Automation
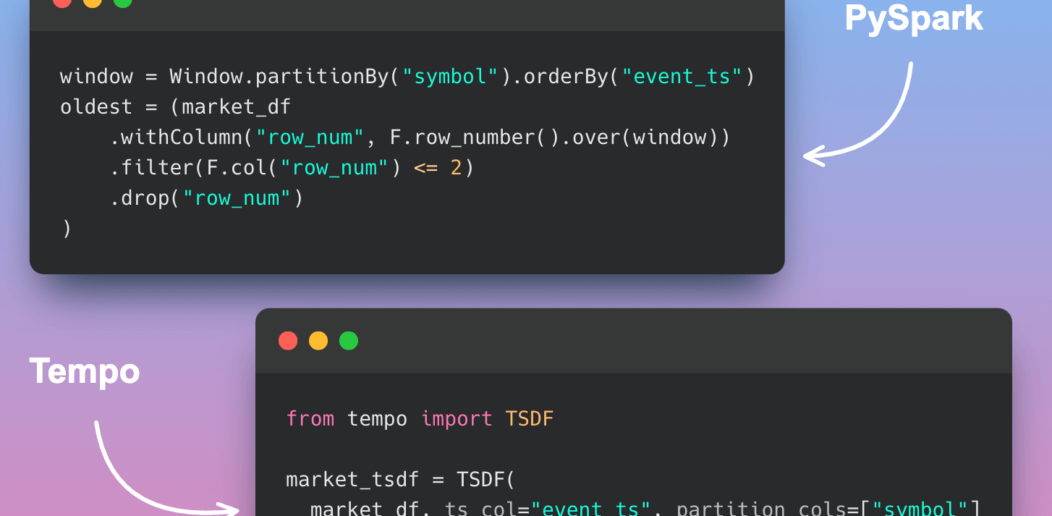
Tempo: Simplified Time Series Analysis in PySpark
Transform Single Inputs into Tables Using PySpark UDTFs
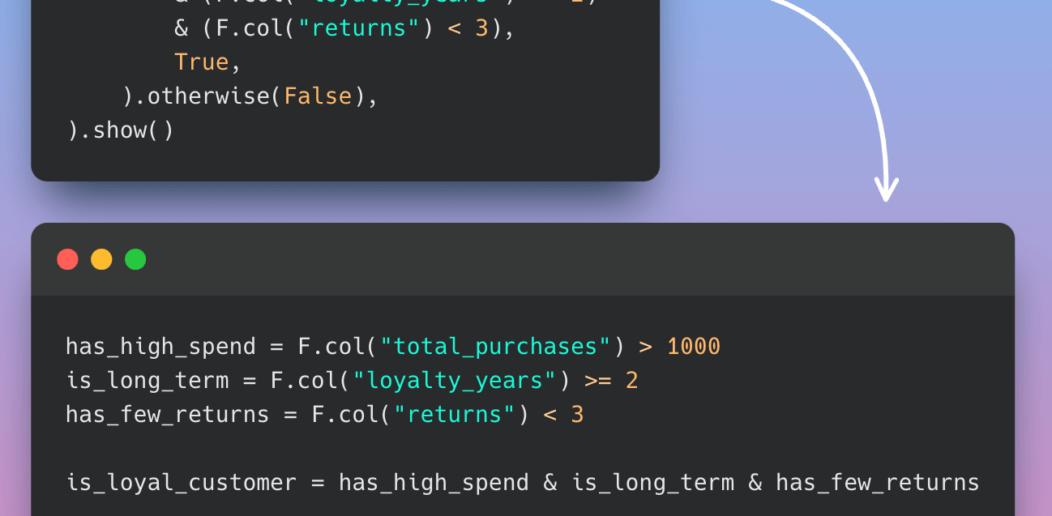
PySpark Best Practices: Simplifying Logical Chain Conditions
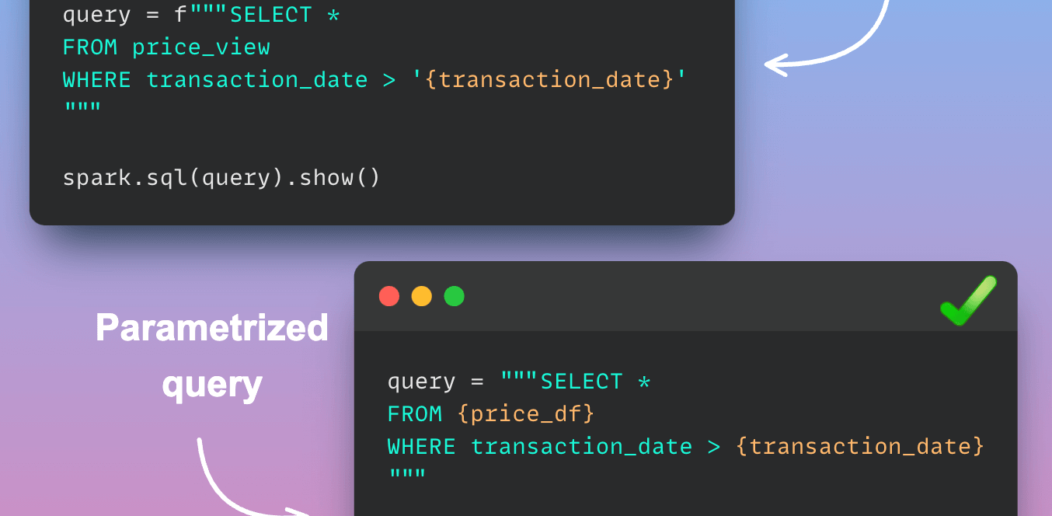
Writing Safer and Cleaner Spark SQL with PySpark’s Parameterized Queries
3 Powerful Ways to Create PySpark DataFrames
PySpark DataFrame Transformations: select vs withColumn
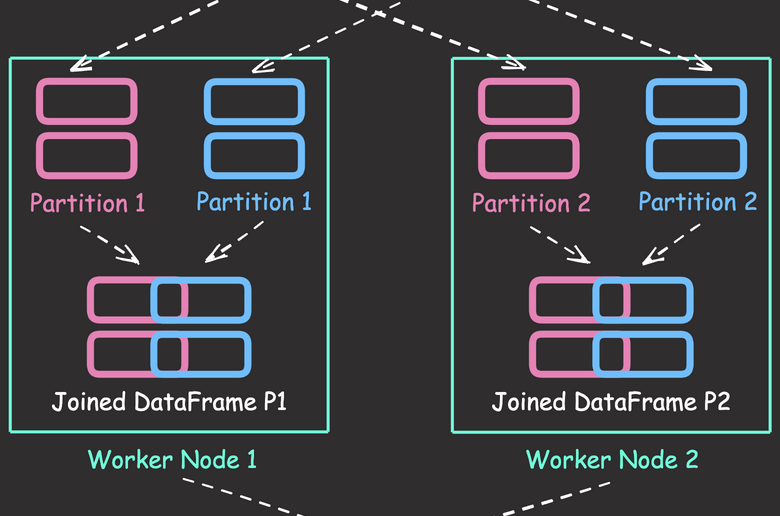
Distributed Data Joining with Shuffle Joins in PySpark
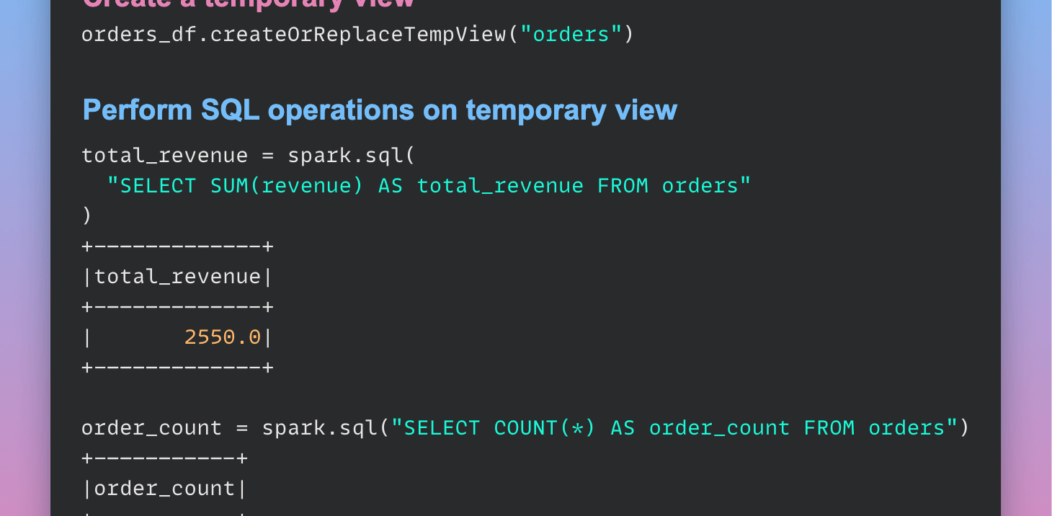
Enhance Code Modularity and Reusability with Temporary Views in PySpark
Optimizing PySpark Queries: DataFrame API or SQL?
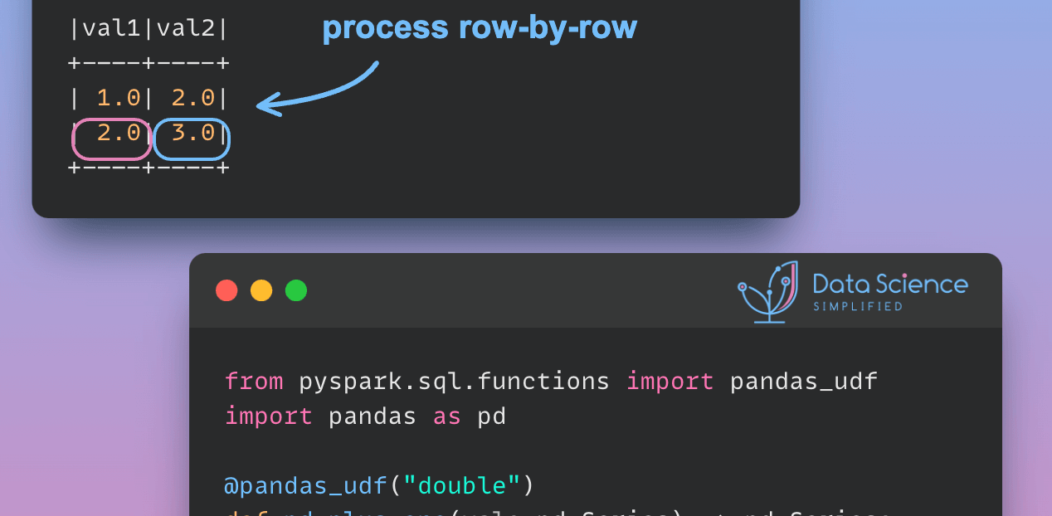
Vectorized Operations in PySpark: pandas_udf vs Standard UDF
>
Scroll to Top
Work with Khuyen Tran
Enter Your Total Budget
Please explain the goals of you campaign
Why Do you want to collaborate with Khuyen Tran
Add date preferences
Enter your contact details
Submit
Work with Khuyen Tran
Enter Your Total Budget
Please explain the goals of you campaign
Why Do you want to collaborate with Khuyen Tran
Add date preferences
Enter your contact details
Submit