Skip to content
Browse Tools
Blog
Book
Sponsor
Account
Login
Browse Tools
Blog
Book
Sponsor
Account
Login
👋 Contact Us
Data Analysis & Manipulation
Analyze Data
Manage Data
Feature Engineer
SQL
Machine Learning & AI
Machine Learning
Natural Language Processing
Time Series
LLM
Code Quality
Python Tips
Python Utilities
Code Optimization
DevOps
Testing
Git
Command Line
Environment Management
Better Outputs
Tools
NumPy
Pandas
Polars
PySpark
Delta Lake
DuckDB
Jupyter Notebook
Visualization & Reporting
Dashboard
Visualization
Workflow & Automation
Workflow Automation
Scrape Data
X
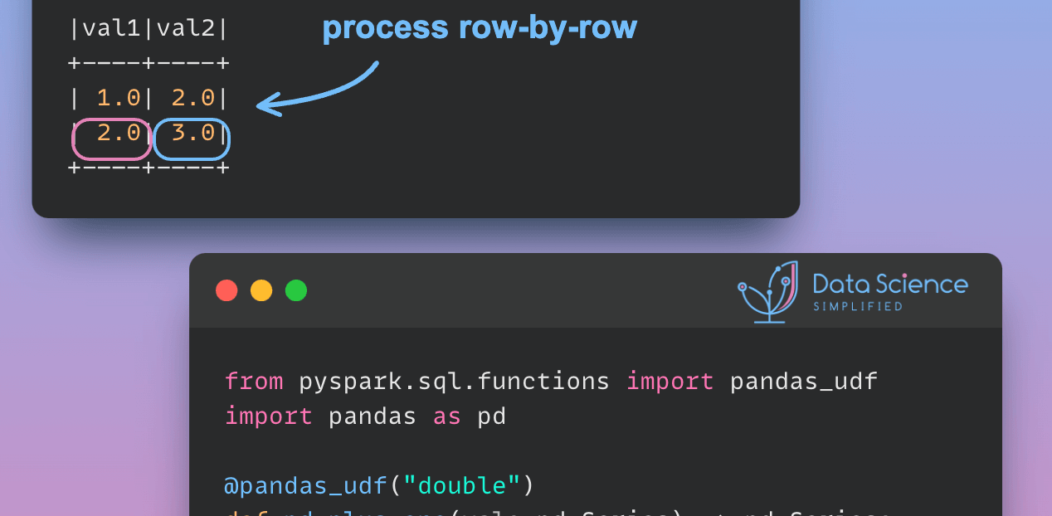
Vectorized Operations in PySpark: pandas_udf vs Standard UDF
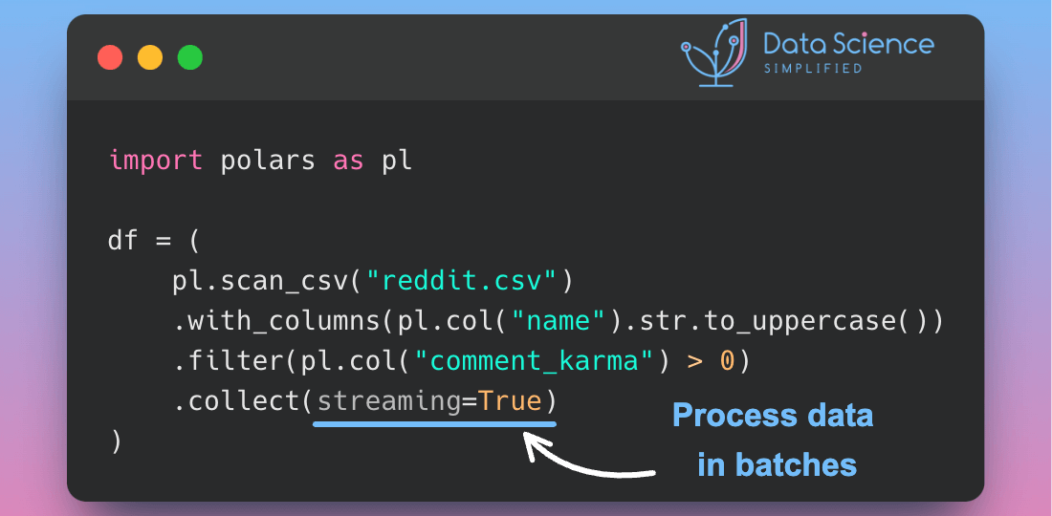
Polars’ Streaming Mode: A Solution for Large Data Sets
Simplify Unit Testing of SQL Queries with PySpark
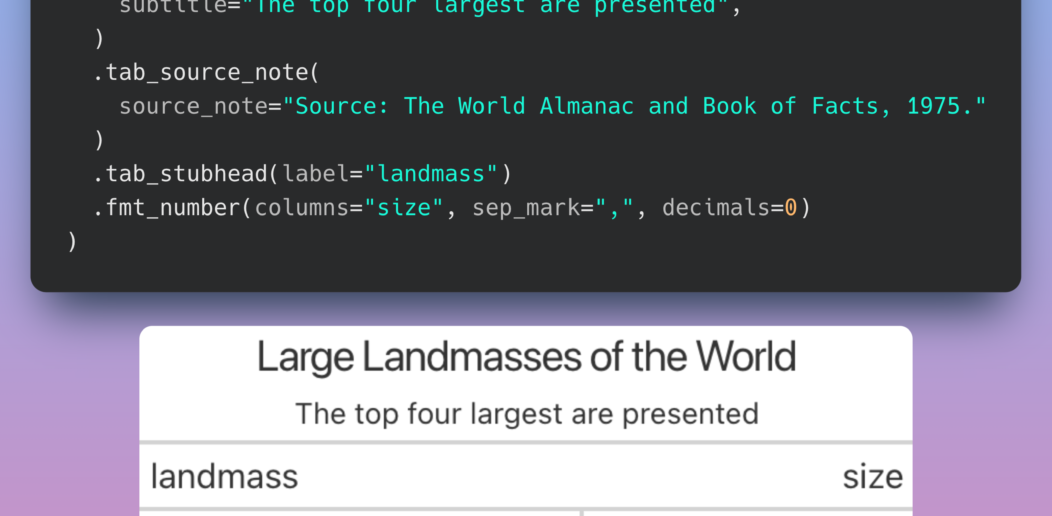
Great Tables: Create Scientific-Looking Tables in Python
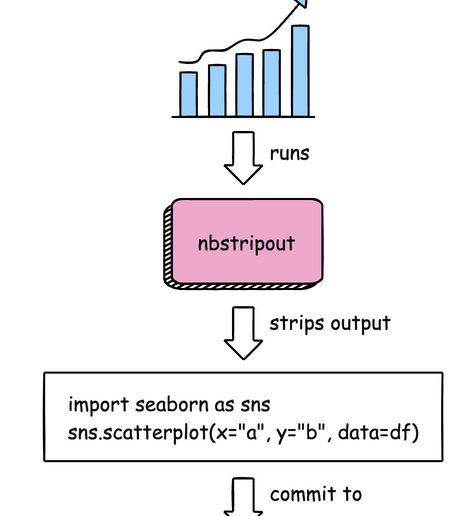
nbstripout: Efficiently Managing Notebook Outputs in Git
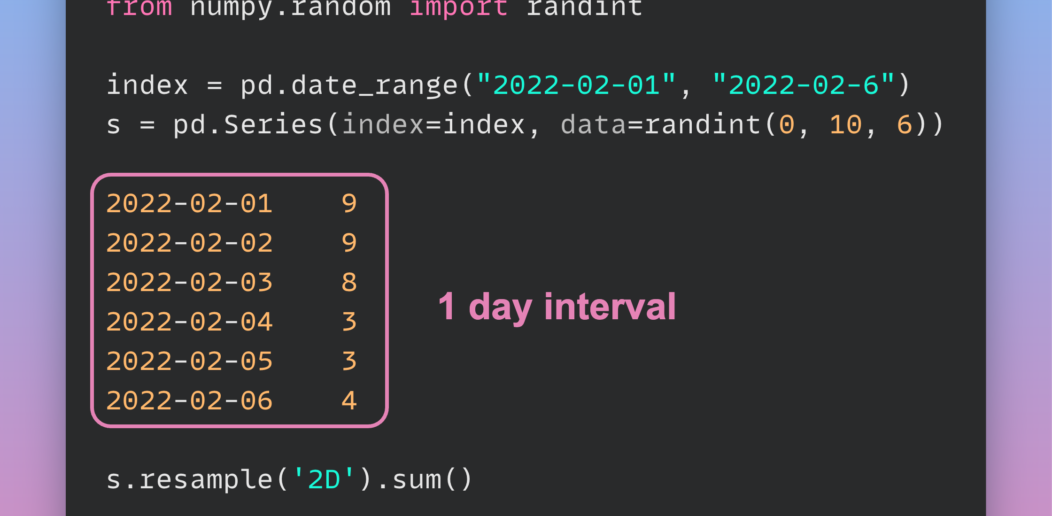
Use Resample to Alter Time-Series Data Frequency
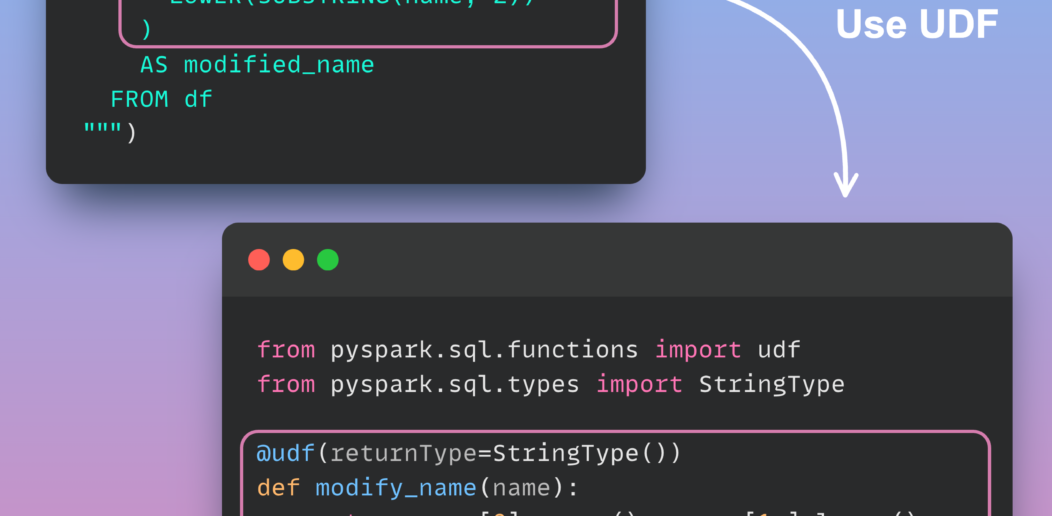
Simplify Complex SQL Queries with PySpark UDFs
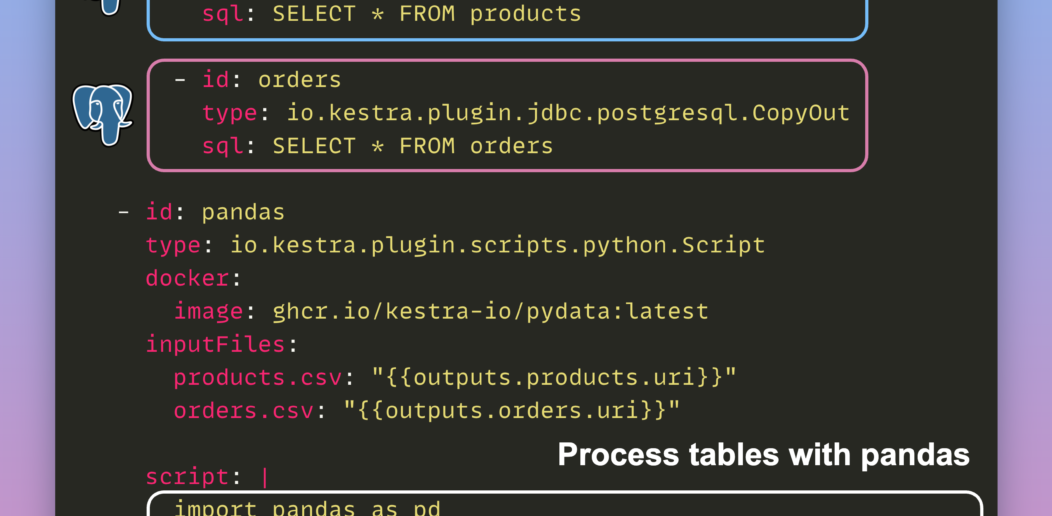
Process Postgres Tables on Schedule with Kestra and Pandas
Enhance Jupyter Notebook Collaboration on GitHub with ReviewNB
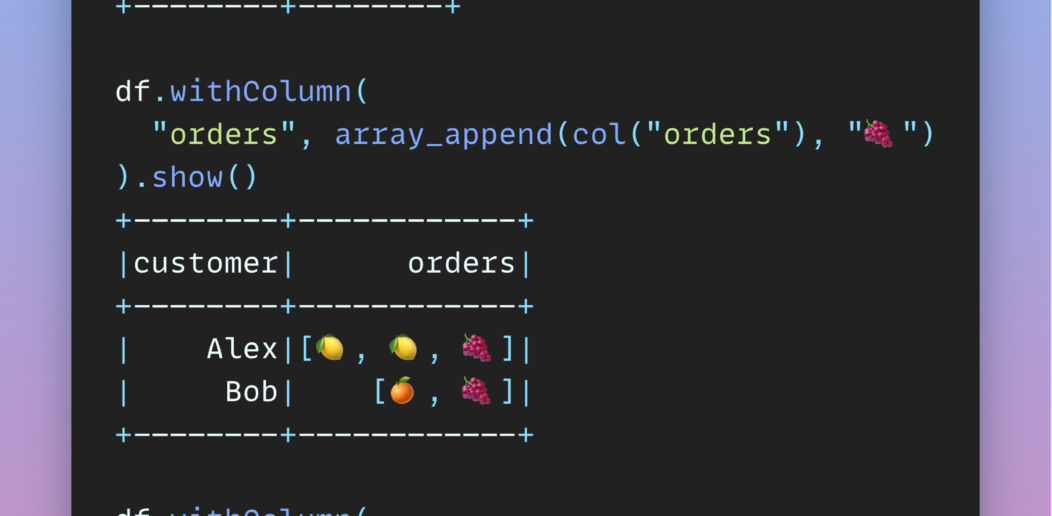
Working with Arrays Made Easier in Spark 3.5
« Previous
Page
1
Page
2
Page
3
Page
4
Page
5
Page
6
Next »
Scroll to Top
Work with Khuyen Tran
Enter Your Total Budget
Please explain the goals of you campaign
Why Do you want to collaborate with Khuyen Tran
Add date preferences
Enter your contact details
Submit
Work with Khuyen Tran
Enter Your Total Budget
Please explain the goals of you campaign
Why Do you want to collaborate with Khuyen Tran
Add date preferences
Enter your contact details
Submit