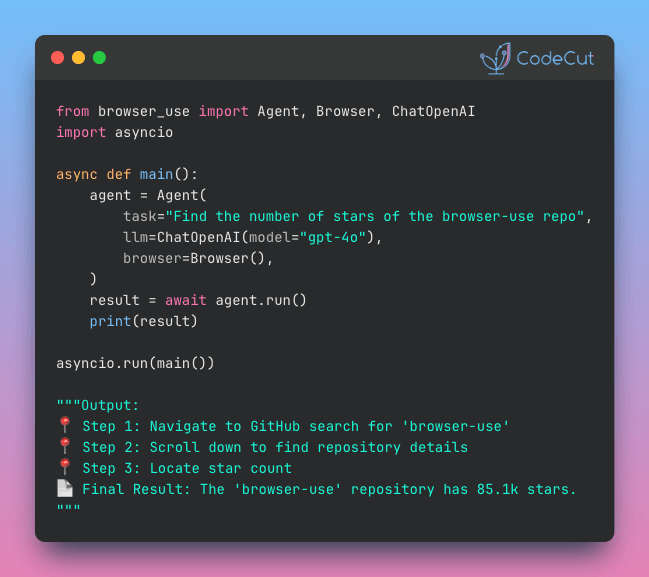
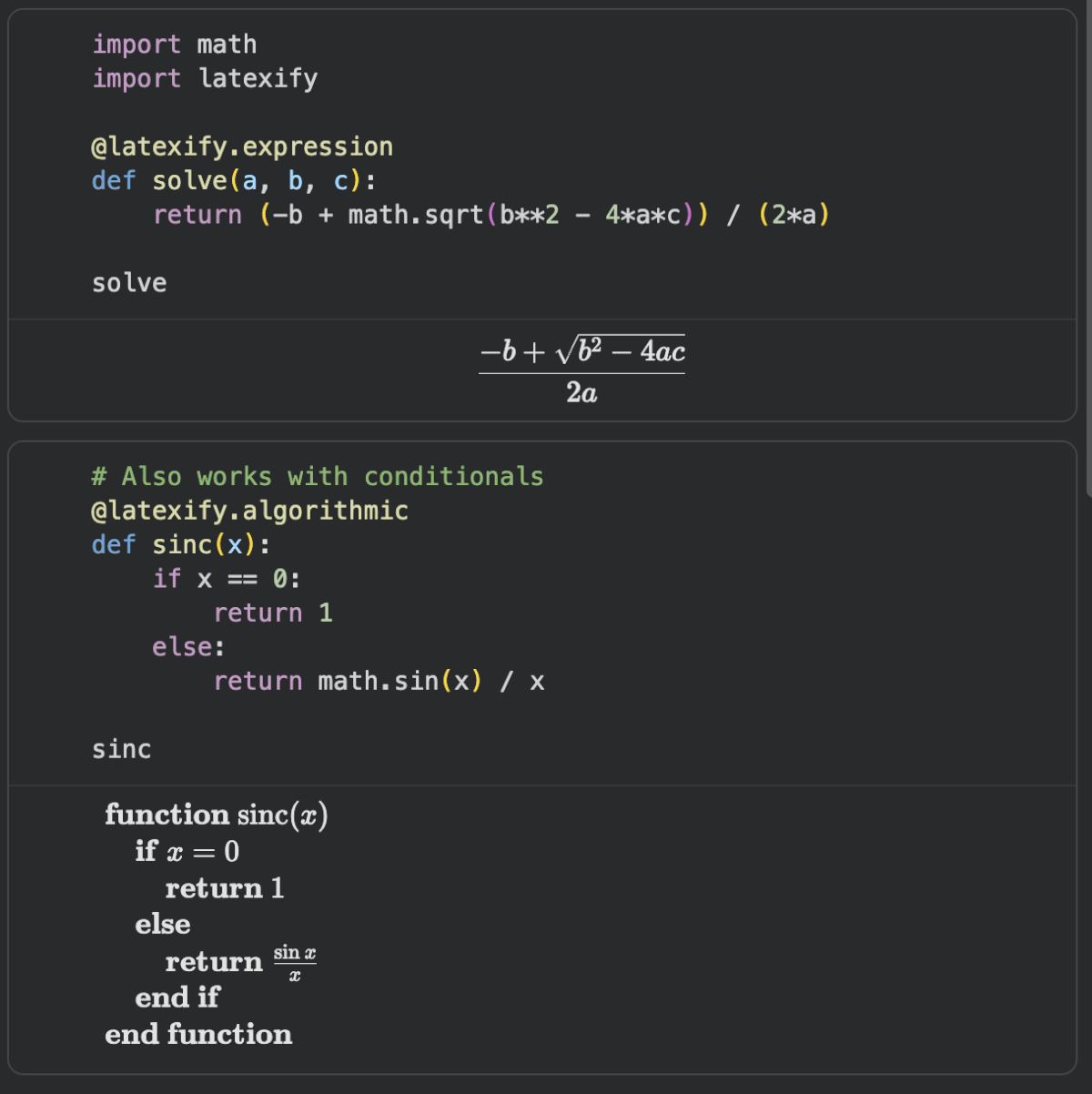
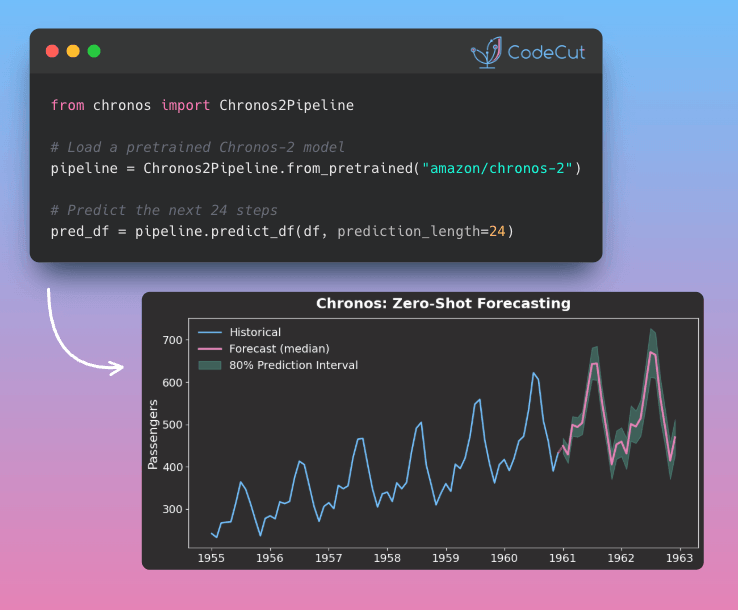
📅 Today’s Picks
Handle Messy Data with RapidFuzz Fuzzy Matching
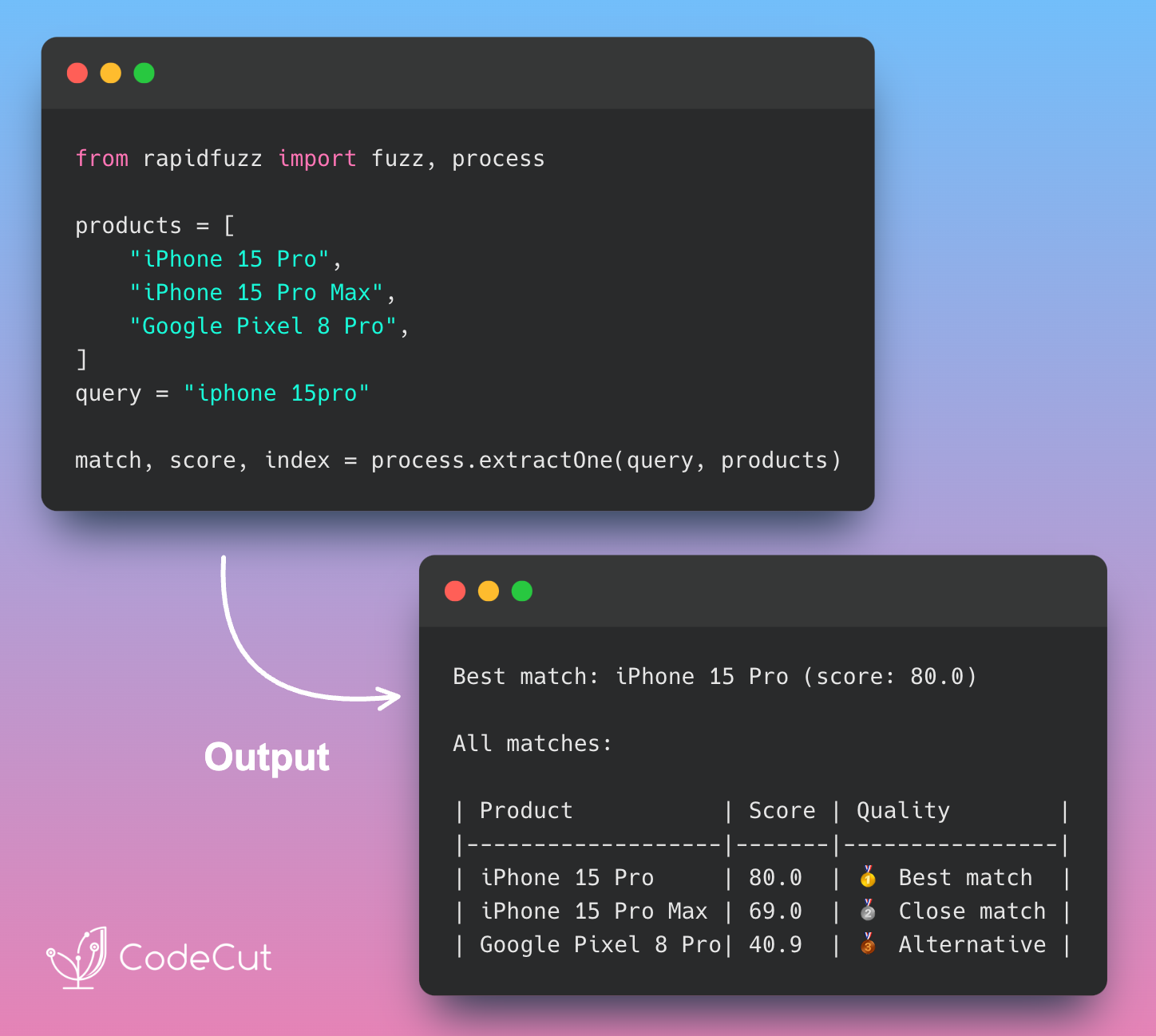
Problem
Traditional regex approaches require hours of preprocessing but still break with common data variations like missing spaces, typos, or inconsistent formatting.
Solution
RapidFuzz eliminates data cleaning overhead with intelligent fuzzy matching.
Key benefits:
- Automatic handling of typos, spacing, and case variations
- Production-ready C++ performance for large datasets
- Full spectrum of fuzzy algorithms in one library
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.