Newsletter #306: TimescaleDB: Turn PostgreSQL into a Time-Series Engine with One Extension
Grab your coffee. Here are this week’s highlights.
📅 Today’s Picks
TimescaleDB: Turn PostgreSQL into a Time-Series Engine with One Extension (Sponsored)
Problem
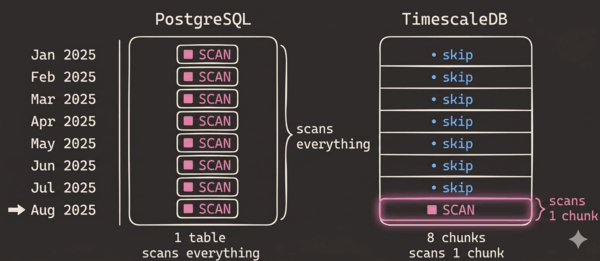
In standard PostgreSQL, all rows live in one table. As time-series data grows into the millions, queries cannot skip irrelevant data, so even recent lookups scan far more than needed.
Solution
TimescaleDB solves this with hypertables, which automatically partition data into time-based chunks.
Queries only touch the relevant chunks, leaving the rest untouched.
Other capabilities:
Shrink storage by up to 95% with columnar compression that stays fully queryable
Faster queries with continuous aggregates that refresh only new data
Built-in retention policies to automatically remove old data
Guidance: One Function for Clean LLM Labels
Problem
Classification tasks with LLMs can get messy. Instead of a clean label, you might get “Option A”, “The answer is A”, or a full explanation.
Cleaning this up requires extra parsing, retries, and validation that can make your system fragile.
Solution
With Guidance, the select() function constrains the model to return exactly one option from your list.
Key benefits:
Guarantees output matches one of your predefined options
Eliminate parsing code and regex patterns
Works with any list of valid choices
☕️ Weekly Finds
TimesFM
[ML]
– Pretrained time-series foundation model by Google Research for zero-shot forecasting
timesketch
[Data Processing]
– Collaborative forensic timeline analysis tool
Orbit
[ML]
– Bayesian time series forecasting with an intuitive initialize-fit-predict interface
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.
.codecut-subscribe-form .codecut-input {
background: #2F2D2E !important;
border: 1px solid #72BEFA !important;
color: #FFFFFF !important;
}
.codecut-subscribe-form .codecut-input::placeholder {
color: #999999 !important;
}
.codecut-subscribe-form .codecut-subscribe-btn {
background: #72BEFA !important;
color: #2F2D2E !important;
}
.codecut-subscribe-form .codecut-subscribe-btn:hover {
background: #5aa8e8 !important;
}
.codecut-subscribe-form {
max-width: 650px;
display: flex;
flex-direction: column;
gap: 8px;
}
.codecut-input {
-webkit-appearance: none;
-moz-appearance: none;
appearance: none;
background: #FFFFFF;
border-radius: 8px !important;
padding: 8px 12px;
font-family: ‘Comfortaa’, sans-serif !important;
font-size: 14px !important;
color: #333333;
border: none !important;
outline: none;
width: 100%;
box-sizing: border-box;
}
input[type=”email”].codecut-input {
border-radius: 8px !important;
}
.codecut-input::placeholder {
color: #666666;
}
.codecut-email-row {
display: flex;
align-items: stretch;
height: 36px;
gap: 8px;
}
.codecut-email-row .codecut-input {
flex: 1;
}
.codecut-subscribe-btn {
background: #72BEFA;
color: #2F2D2E;
border: none;
border-radius: 8px;
padding: 8px 14px;
font-family: ‘Comfortaa’, sans-serif;
font-size: 14px;
font-weight: 500;
cursor: pointer;
text-decoration: none;
display: flex;
align-items: center;
justify-content: center;
transition: background 0.3s ease;
}
.codecut-subscribe-btn:hover {
background: #5aa8e8;
}
.codecut-subscribe-btn:disabled {
background: #999;
cursor: not-allowed;
}
.codecut-message {
font-family: ‘Comfortaa’, sans-serif;
font-size: 12px;
padding: 8px;
border-radius: 6px;
display: none;
}
.codecut-message.success {
background: #d4edda;
color: #155724;
display: block;
}
@media (max-width: 480px) {
.codecut-email-row {
flex-direction: column;
height: auto;
gap: 8px;
}
.codecut-input {
border-radius: 8px;
height: 36px;
}
.codecut-subscribe-btn {
width: 100%;
text-align: center;
border-radius: 8px;
height: 36px;
}
}
Subscribe