🤝 COLLABORATION
Learn ML Engineering for Free on ML Zoomcamp
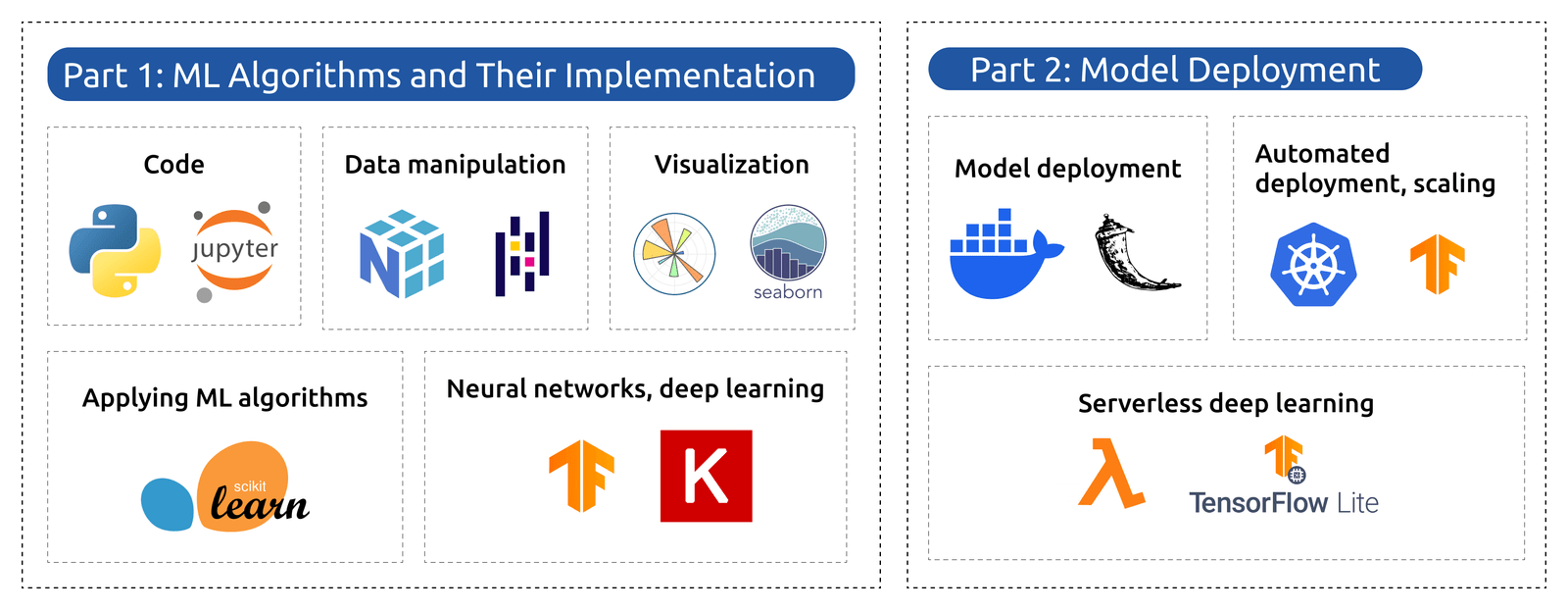
Learn ML engineering for free on ML Zoomcamp and receive a certificate! Join online for practical, hands-on experience with the tech stack and workflows used in production ML. The next cohort of the course starts on September 15, 2025. Here’s what you’ll learn:
Core foundations:
- Python ecosystem: Jupyter, NumPy, Pandas, Matplotlib, Seaborn
- ML frameworks: Scikit-learn, TensorFlow, Keras
Applied projects:
- Supervised learning with CRISP-DM framework
- Classification/regression with evaluation metrics
- Advanced models: decision trees, ensembles, neural nets, CNNs
Production deployment:
- APIs and containers: Flask, Docker, Kubernetes
- Cloud solutions: AWS Lambda, TensorFlow Serving/Lite
📅 Today’s Picks
Stop Loading Full Datasets: Use itertools.islice() for Smart Sampling

Problem
Data prototyping typically requires loading entire datasets into memory first before sampling.
A 1-million-row dataset consumes 7.6 MB of memory even when you only need 10 rows for initial feature exploration, creating unnecessary resource overhead.
Solution
Use itertools.islice() to extract slices from iterators without loading full datasets into memory first.
Key benefits:
- Memory-efficient data sampling
- Faster prototyping workflows
- Less computational load on laptops
From pandas Full Reloads to Delta Lake Incremental Updates

Problem
Processing entire datasets when you only need to add a few new records wastes time and memory.
Pandas lacks incremental append capabilities, requiring full dataset reload for data updates.
Solution
Delta Lake’s append mode processes only new data without touching existing records.
Key advantages:
- Append new records without full dataset reload
- Memory usage scales with new data size, not total dataset size
- Automatic data protection prevents corruption during updates
- Time travel enables rollback to previous dataset versions
Perfect for production data pipelines that need reliable incremental updates.
☕️ Weekly Finds
Semantic Kernel [AI Framework] – Model-agnostic SDK that empowers developers to build, orchestrate, and deploy AI agents and multi-agent systems with enterprise-grade reliability
Ray [Distributed Computing] – AI compute engine with core distributed runtime and AI Libraries for accelerating ML workloads from laptop to cluster
Apache Airflow [Workflow Orchestration] – Platform for developing, scheduling, and monitoring workflows with powerful data pipeline orchestration capabilities
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.