📅 Today’s Picks
PySpark: Avoid Double Conversions with applyInArrow
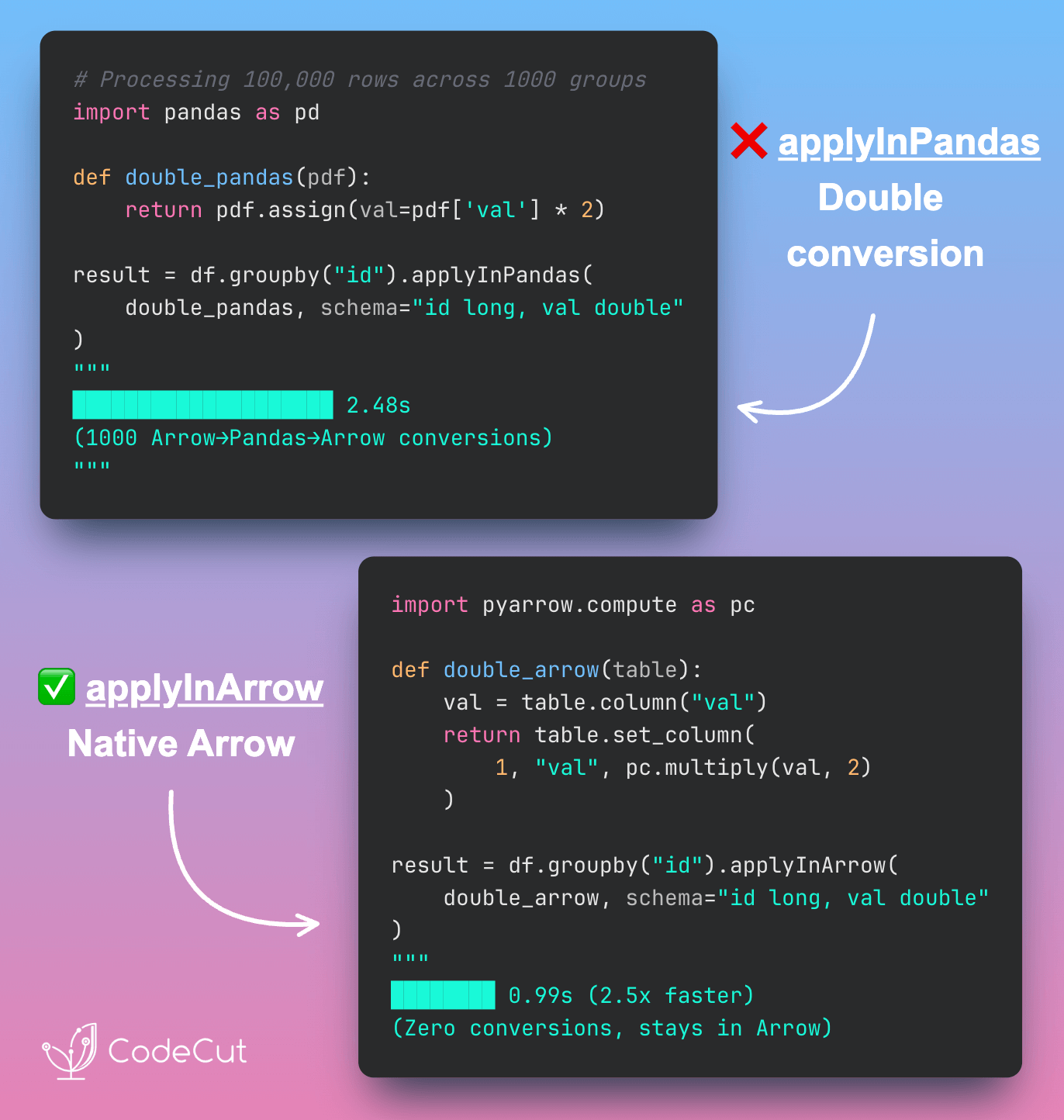
Problem
applyInPandas lets you apply Pandas functions in PySpark by converting data from Arrow→Pandas→Arrow for each operation.
This double conversion adds serialization overhead that slows down your transformations.
Solution
applyInArrow (introduced in PySpark 4.0.0) works directly with PyArrow tables, eliminating the Pandas conversion step entirely.
This keeps data in Arrow’s columnar format throughout the pipeline, making operations significantly faster.
Trade-off: PyArrow’s syntax is less intuitive than Pandas, but it’s worth it if you’re processing large datasets where performance matters.
☕️ Weekly Finds
causal-learn [ML] – Python package for causal discovery that implements both classical and state-of-the-art causal discovery algorithms
POT [ML] – Python Optimal Transport library providing solvers for optimization problems related to signal, image processing and machine learning
qdrant [MLOps] – High-performance, massive-scale Vector Database and Vector Search Engine for the next generation of AI
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.