Grab your coffee. Here are this week’s highlights.
📅 Today’s Picks
Bandit: Catch Insecure Patterns in AI-Generated Python Code
Problem
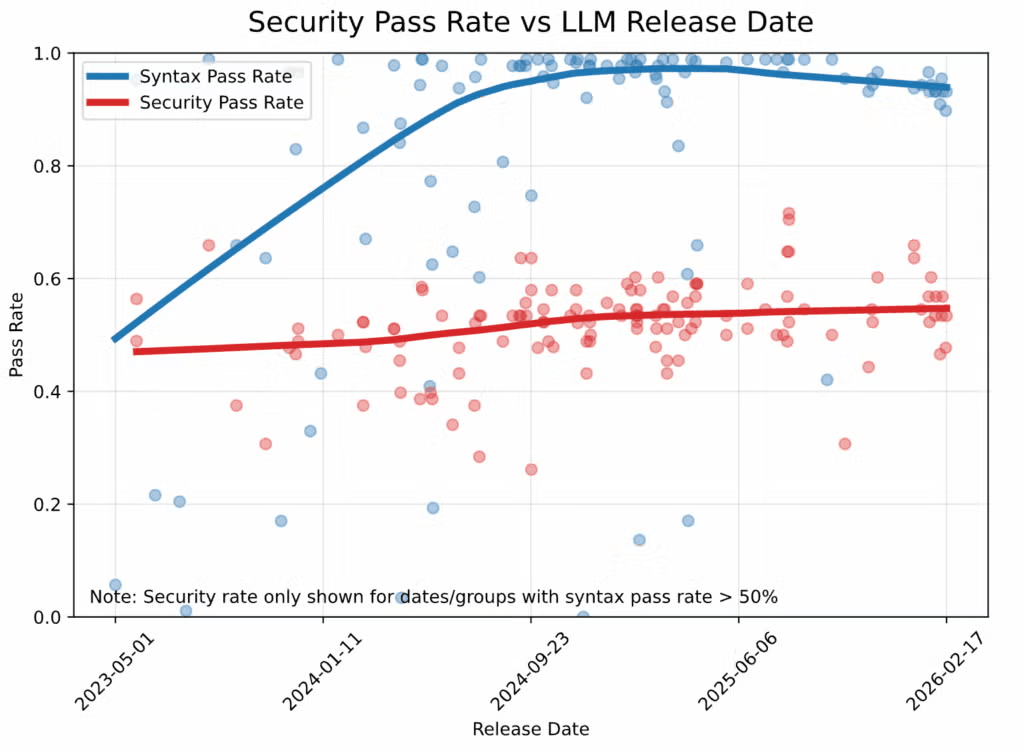
LLMs have become extremely good at generating syntactically valid Python, but security quality has barely improved.
Veracode’s Spring 2026 GenAI Code Security Report found that security pass rates have remained stuck near 55% since 2024.
That gap exists because models learn from public code full of insecure patterns and reproduce them when prompted.
At the same time, reviewers usually verify whether code works, not whether it introduces vulnerabilities.
Solution
Bandit is a static analyzer for Python that identifies insecure patterns by matching code against 60+ Common Weakness Enumeration (CWE) rules.
Key capabilities:
- Flags hardcoded secrets, weak hashes (MD5, SHA1), and unsafe deserialization
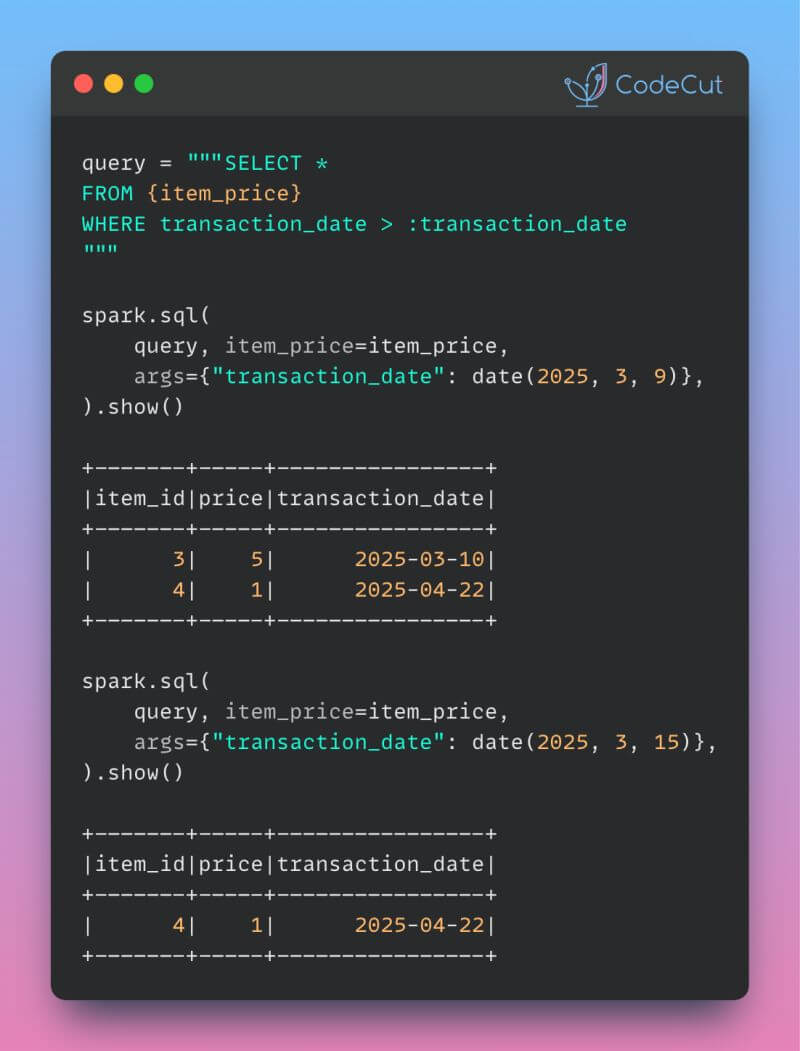
- Detects SQL string concatenation,
eval, andexecinjection risks - Catches empty
exceptblocks and unpinned Hugging Face downloads - Integrates with pre-commit hooks and GitHub Actions out of the box
- Maps every finding to a CWE ID so issues stay auditable
llama.cpp: Run LLMs 70% Faster Than Ollama on the Same GPU
Problem
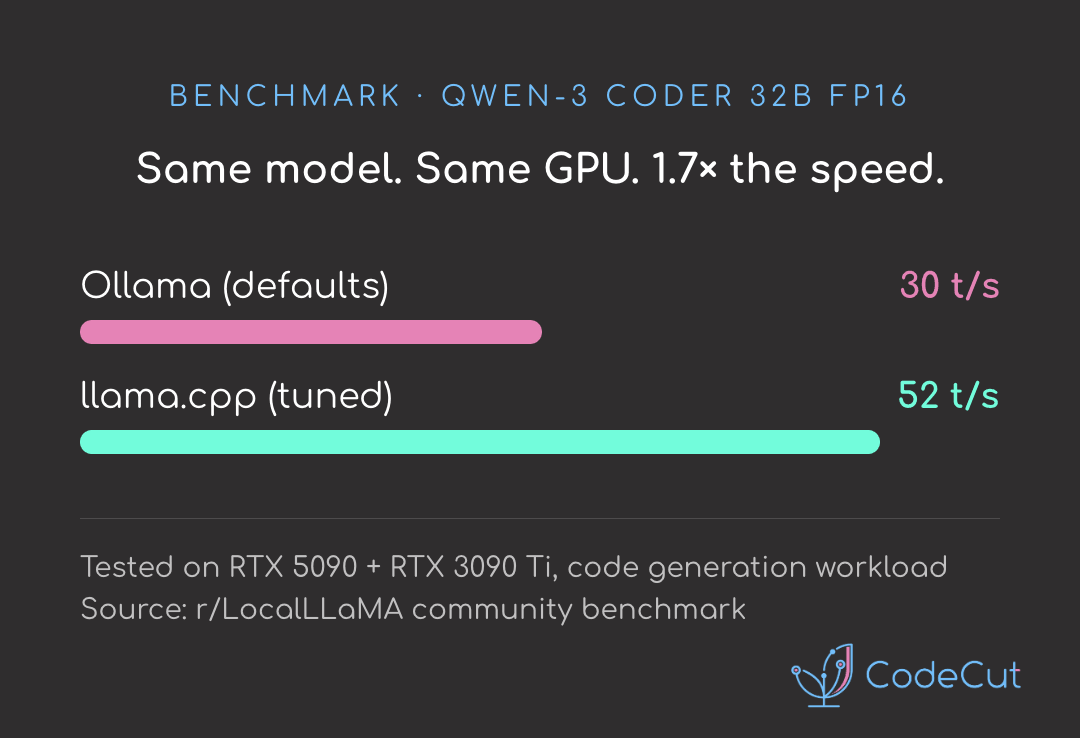
An r/LocalLLaMA benchmark on Qwen-3 Coder 32B (FP16) measured Ollama at 30 tokens/sec and llama.cpp at 52 tokens/sec on the same model and hardware.
Ollama is built on top of llama.cpp, so the core inference engine is identical. The performance gap comes from configuration.
Solution
Ollama ships with conservative defaults designed to work reliably across many systems. llama.cpp exposes the low-level tuning flags so you can optimize specifically for your hardware.
Key flags to tune:
- GPU offload (
-ngl 99): put the entire model on your GPU instead of partial offload - Throughput (
--batch-size): bigger means faster prompts but more GPU memory - Context length (
--cache-type-k q4): use less GPU memory per token so longer prompts fit - Generation speed (
-md): run a small helper model alongside your main model for 2-3x faster generation
📚 Latest Deep Dives
Bandit: Audit AI-Generated Python for Security Flaws
LLMs have become extremely good at generating syntactically valid Python, but security quality has barely improved.
Veracode’s Spring 2026 GenAI Code Security Report found that security pass rates have remained stuck near 55% since 2024.
That gap exists because models learn from public code full of insecure patterns and reproduce them when prompted.
At the same time, reviewers usually verify whether code works, not whether it introduces vulnerabilities.
Bandit is a static analyzer for Python that identifies insecure patterns by matching code against 60+ Common Weakness Enumeration (CWE) rules.
This article walks through 8 common anti-patterns in AI-generated Python and how to fix them with Bandit.
☕️ Weekly Finds
scalene [Code Quality] – A high-performance CPU, GPU, and memory profiler for Python with AI-powered optimization proposals.
pymc-marketing [Data Analysis] – Bayesian marketing toolbox in PyMC. Includes Media Mix Modeling (MMM), customer lifetime value (CLV), and buy-till-you-die (BTYD) models.
cronboard [Workflow Automation] – A terminal-based dashboard for managing cron jobs locally and on remote servers. Add, edit, pause, resume, and search jobs from the terminal.
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.