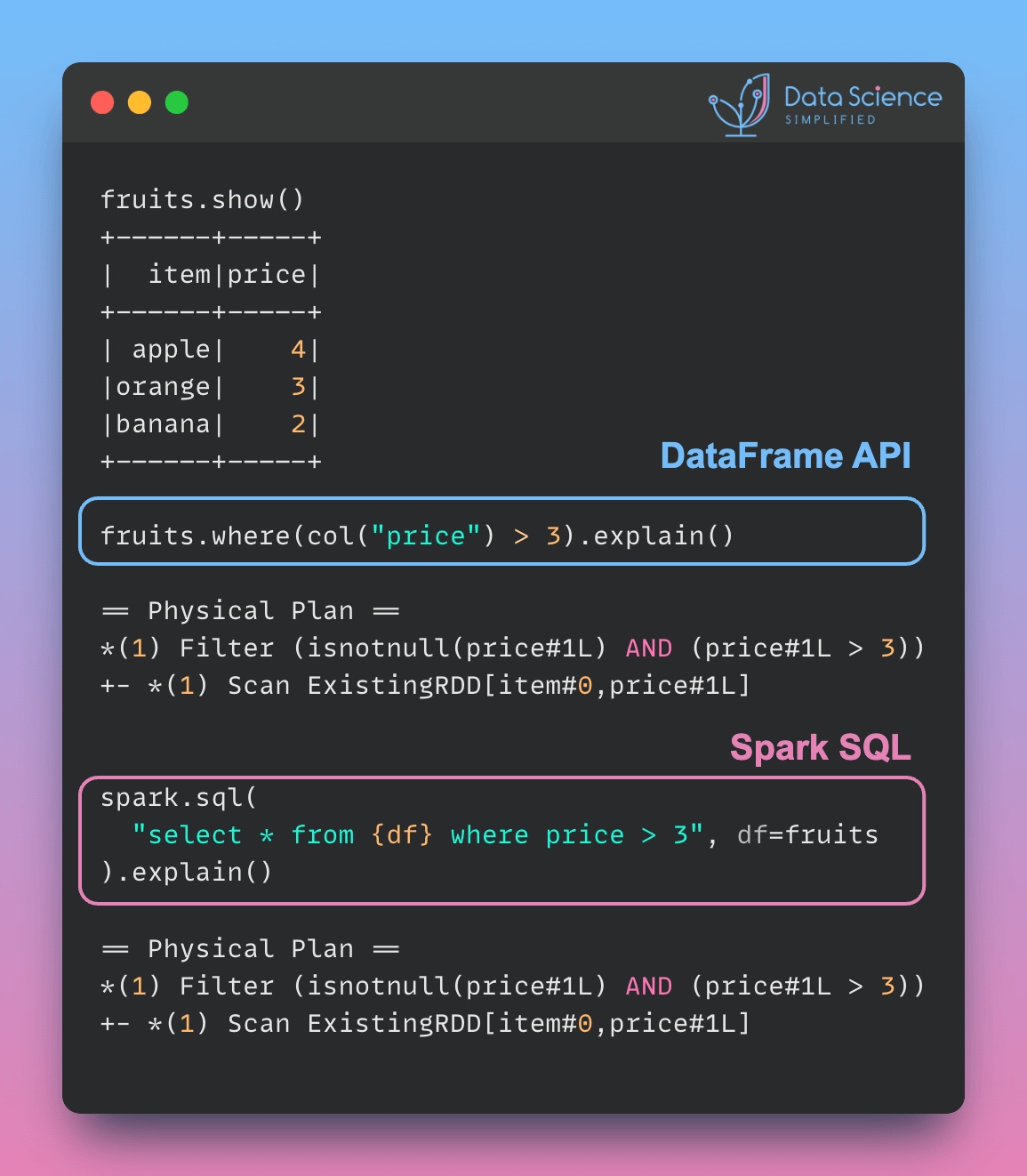

PySpark queries with different syntax (DataFrame API or parameterized SQL) can have the same performance, as the physical plan is identical. Here is an example:
from pyspark.sql.functions import col
fruits = spark.createDataFrame(
[("apple", 4), ("orange", 3), ("banana", 2)], ["item", "price"]
)
fruits.show()Use the DataFrame API to filter rows where the price is greater than 3.
fruits.where(col("price") > 3).explain()== Physical Plan ==
*(1) Filter (isnotnull(price#1L) AND (price#1L > 3))
+- *(1) Scan ExistingRDD[item#0,price#1L]Use the spark.sql() method to execute an equivalent SQL query.
spark.sql("select * from {df} where price > 3", df=fruits).explain()== Physical Plan ==
*(1) Filter (isnotnull(price#1L) AND (price#1L > 3))
+- *(1) Scan ExistingRDD[item#0,price#1L]The physical plan for both queries is the same, indicating identical performance.
The choice between DataFrame API and spark.sql() depends on the following:
- Familiarity: Use
spark.sql()if your team prefers SQL syntax. Use the DataFrame API if chained method calls are more intuitive for your team. - Complexity of Transformations: The DataFrame API is more flexible for complex manipulations, while SQL is more concise for simpler queries.


