Grab your coffee. Here are this week’s highlights.
📅 Today’s Picks
LiteLLM – One interface for OpenAI, Anthropic, and Gemini

Problem
Frameworks like LangChain and LlamaIndex are useful when you need chains, agents, retrieval, memory, or orchestration.
But if you only need to call different providers through the same interface, you may not want to restructure your app around a full LLM framework.
Solution
LiteLLM solves this as a lightweight interface layer.
You can keep one completion() call across 100+ providers, then switch models by changing only the model string.
Polars 1.41 – Speed Up Wide Parquet Scans Without Code Changes
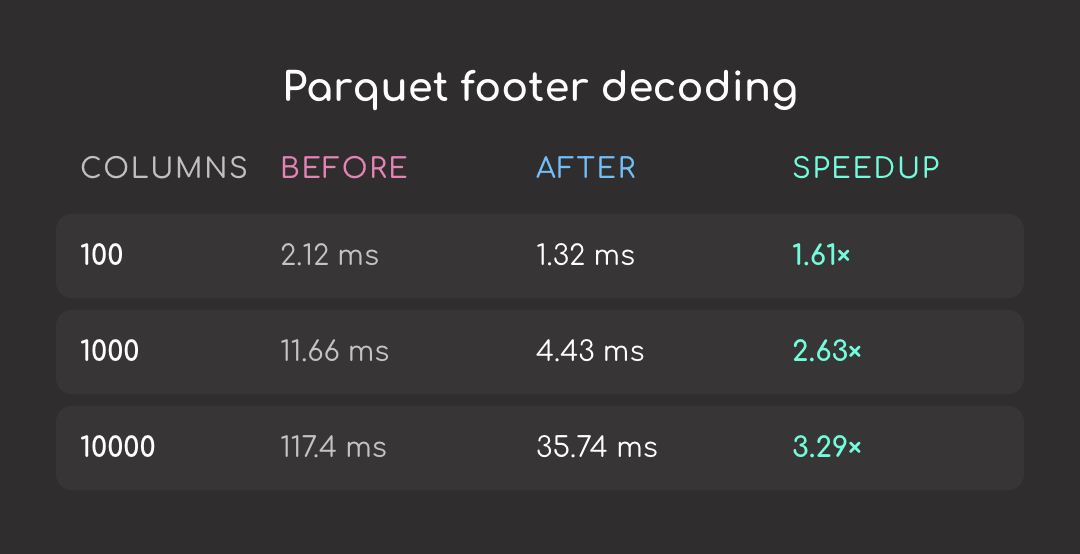
Problem
scan_parquet is Polars’ lazy way to read a Parquet file, allowing it to optimize the query before loading data.
Before the query runs, Polars still needs to decode the Parquet footer to understand the schema, row groups, and column statistics. For very wide files, that setup step can take noticeable time.
Solution
Polars 1.41 makes scan_parquet faster by replacing the old metadata decoder with one built specifically for Parquet files.
In the Polars 1.41 release benchmark, footer decoding was up to 3.29x faster on a 10,000-column file.
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.