DuckDB + PyArrow: 2900x Faster Than pandas for Large Dataset Processing
DuckDB optimizes query execution with multiple optimizations, while PyArrow efficiently manages in-memory data processing and storage. Combining DuckDB and PyArrow allows you to efficiently process datasets larger than memory on a single machine.
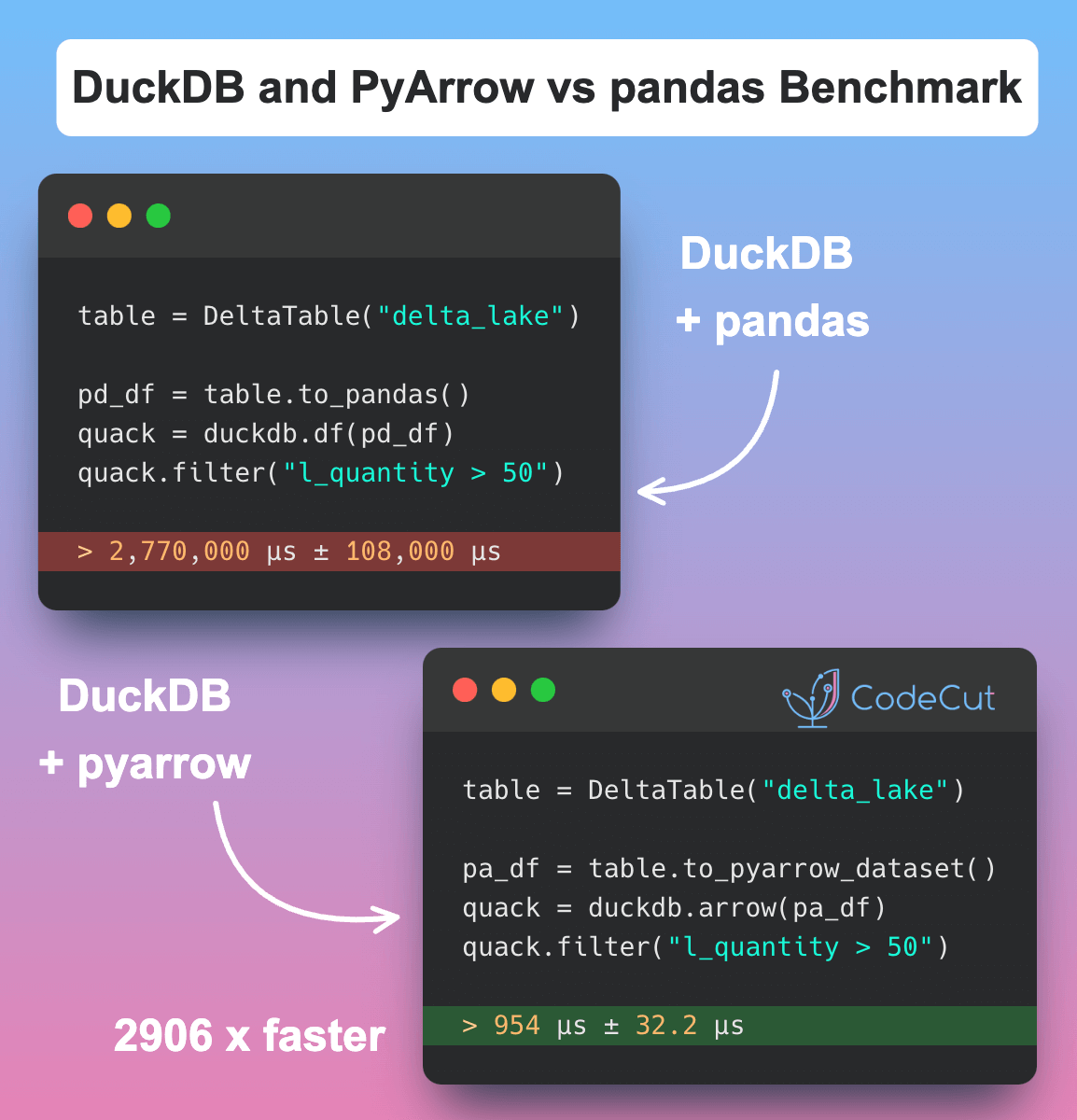
In the code above, we convert a Delta Lake table with over 6 million rows to a pandas DataFrame and a PyArrow dataset, which are then used by DuckDB.
Running DuckDB on a PyArrow dataset is approximately 2906 times faster than running DuckDB on a pandas DataFrame.
DuckDB + PyArrow: 2900x Faster Than pandas for Large Dataset Processing Read More »