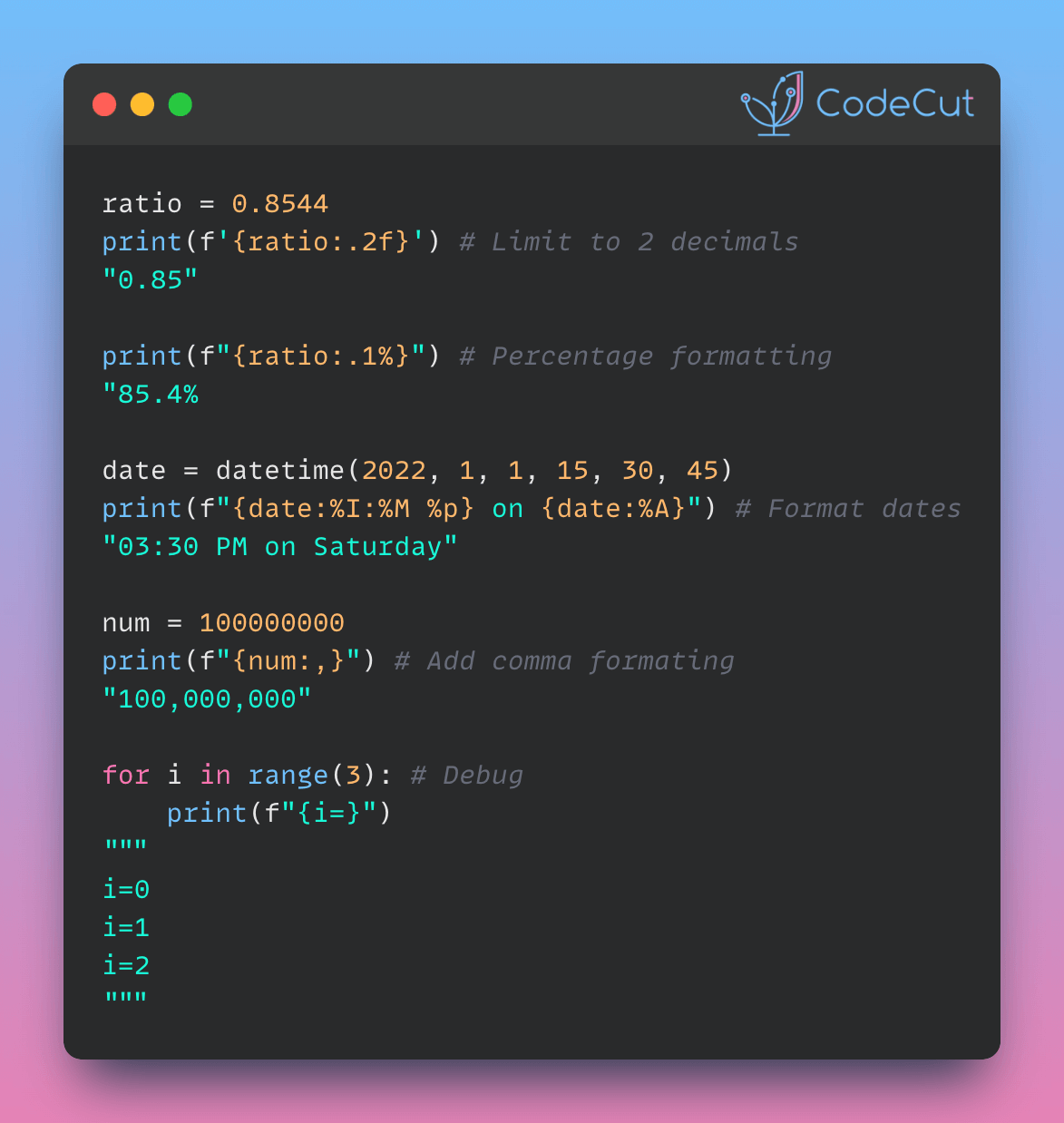
Python offers several built-in data structures that are essential for efficient programming. In this guide, we’ll explore four fundamental structures: tuples, lists, sets, and dictionaries. We’ll discuss their characteristics, use cases, and how to work with them effectively.
Tuples: Immutable Sequences
Tuples are immutable sequences, meaning once created, they cannot be modified.
Key Characteristics:
Ordered
Immutable
Allow duplicates
Support indexing
When to Use Tuples:
When immutability is required (e.g., as dictionary keys)
To ensure data integrity
To return multiple values from a function
Example:
coordinates = (40.7128, -74.0060)
city_info = {
coordinates: "New York City"
}
print(city_info[coordinates]) # Output: New York City
Lists: Versatile Mutable Sequences
Lists are ordered collections that can store various object types and be modified after creation.
Key Characteristics:
Ordered
Mutable
Allow duplicates
Support indexing
When to Use Lists:
When order matters
When you need to modify the collection
When duplicates are allowed
Example:
stock_prices = [100, 101, 102, 103, 100]
stock_prices.append(99)
print(stock_prices) # Output: [100, 101, 102, 103, 100, 99]
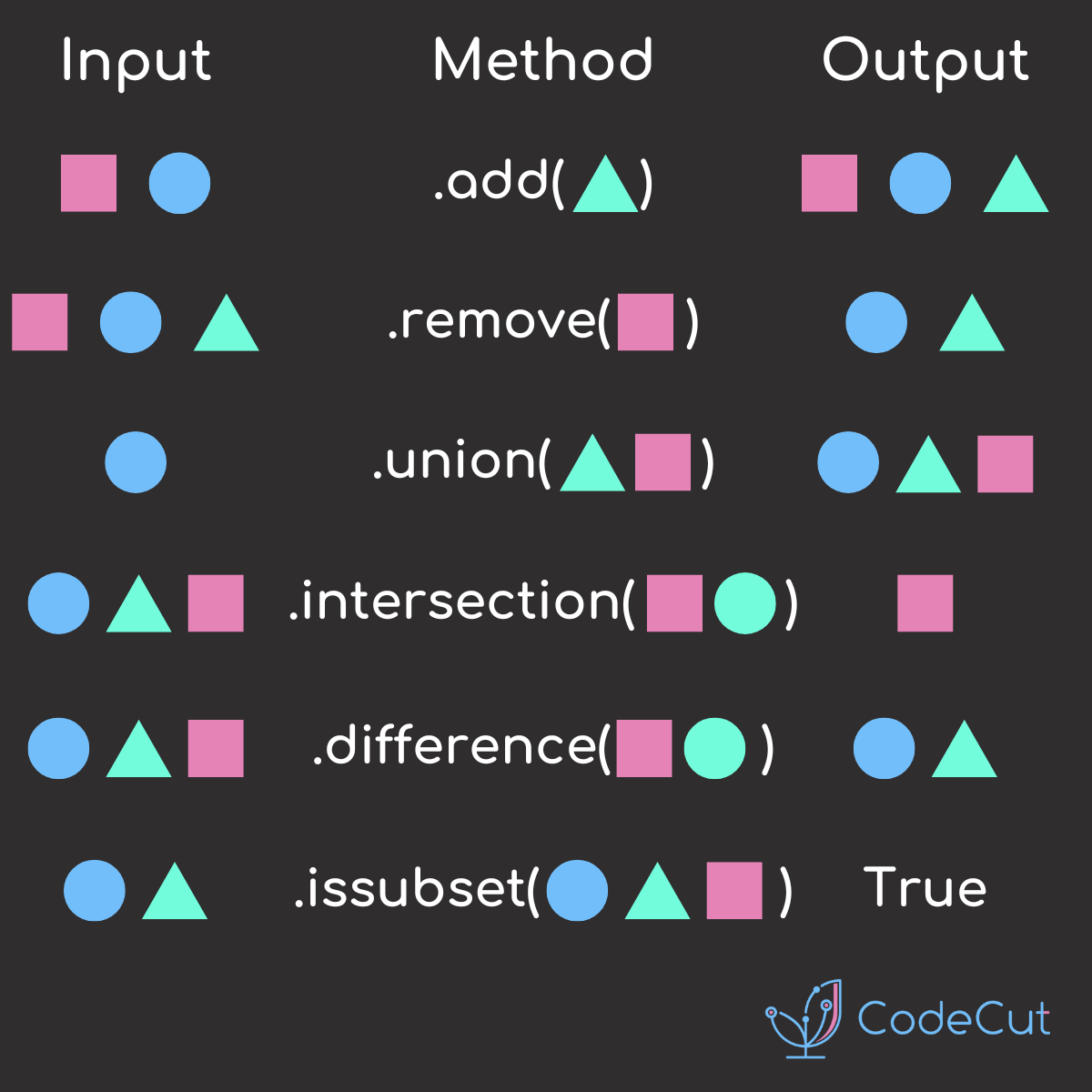
Sets: Unique, Unordered Collections
Sets are unordered collections of unique elements.
Key Characteristics:
Unordered
Mutable
No duplicates
No indexing
When to Use Sets:
To ensure uniqueness
For mathematical set operations
For efficient membership testing
Example:
fruits = {"apple", "banana", "cherry"}
fruits.add("date")
fruits.update(["elderberry", "fig"])
fruits.remove("banana")
print(fruits) # Output: {'apple', 'cherry', 'date', 'elderberry', 'fig'}
Dictionaries: Key-Value Pairs
Dictionaries are collections of key-value pairs.
Key Characteristics:
Ordered (as of Python 3.7+)
Mutable
No duplicate keys
Keys must be immutable
When to Use Dictionaries:
For efficient key-based lookups
To store related data as key-value pairs
Example:
car = {
"make": "Toyota",
"model": "Corolla",
"year": 2020
}
car["color"] = "blue"
car.pop("year")
print(car) # Output: {'make': 'Toyota', 'model': 'Corolla', 'color': 'blue'}
Performance Considerations
Set membership testing is generally faster than list membership testing, especially for large collections.
Dictionary key lookups are very efficient.
Copying vs. Referencing
When assigning one variable to another, be aware of whether you’re creating a new reference or a copy:
# Referencing (both variables point to the same object)
list1 = [1, 2, 3]
list2 = list1
# Copying (creates a new object)
list3 = list1.copy()
By understanding these data structures and their properties, you can choose the most appropriate one for your specific programming needs, leading to more efficient and readable code.