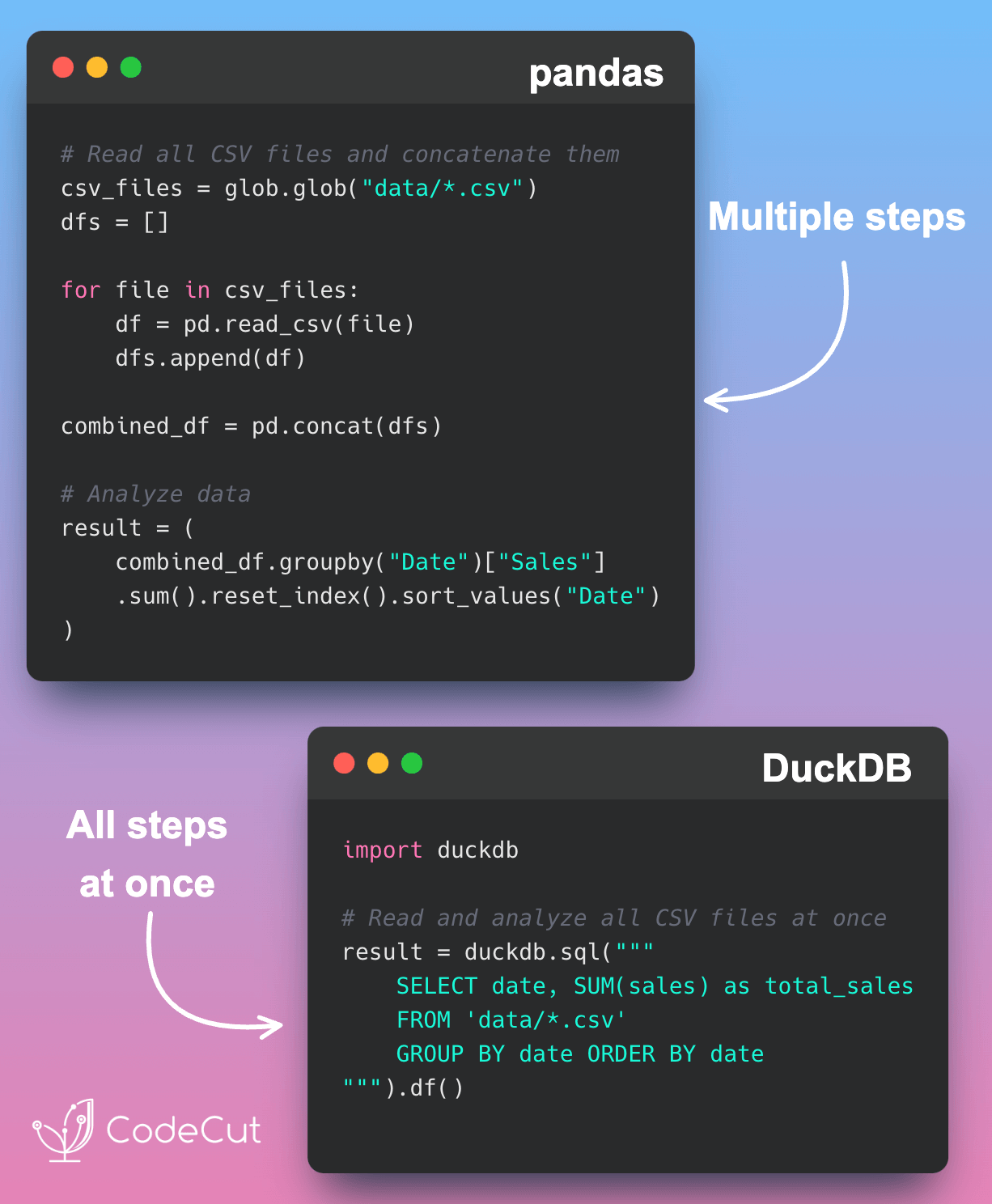
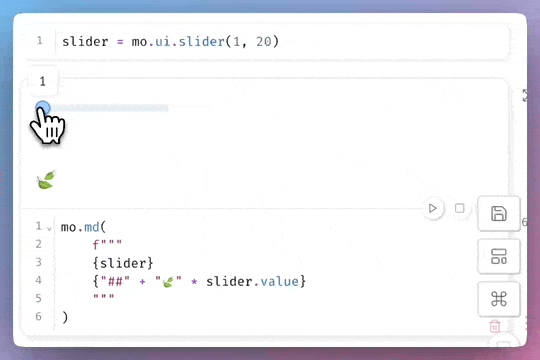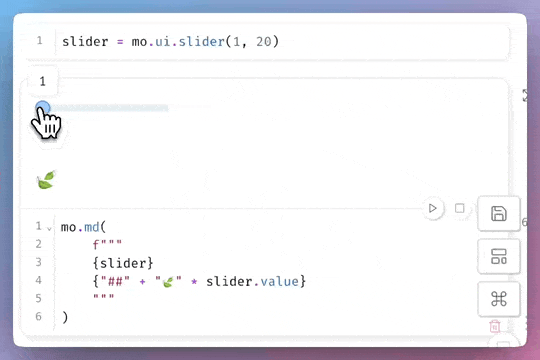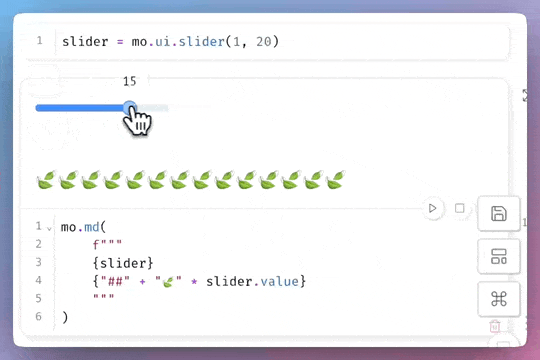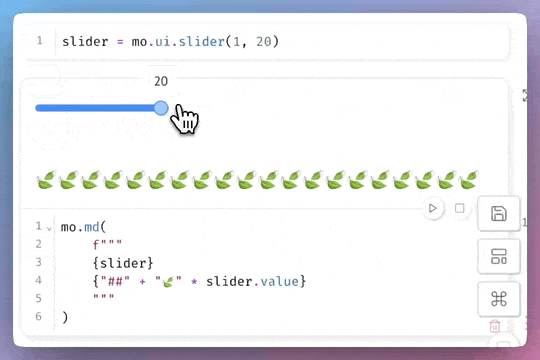
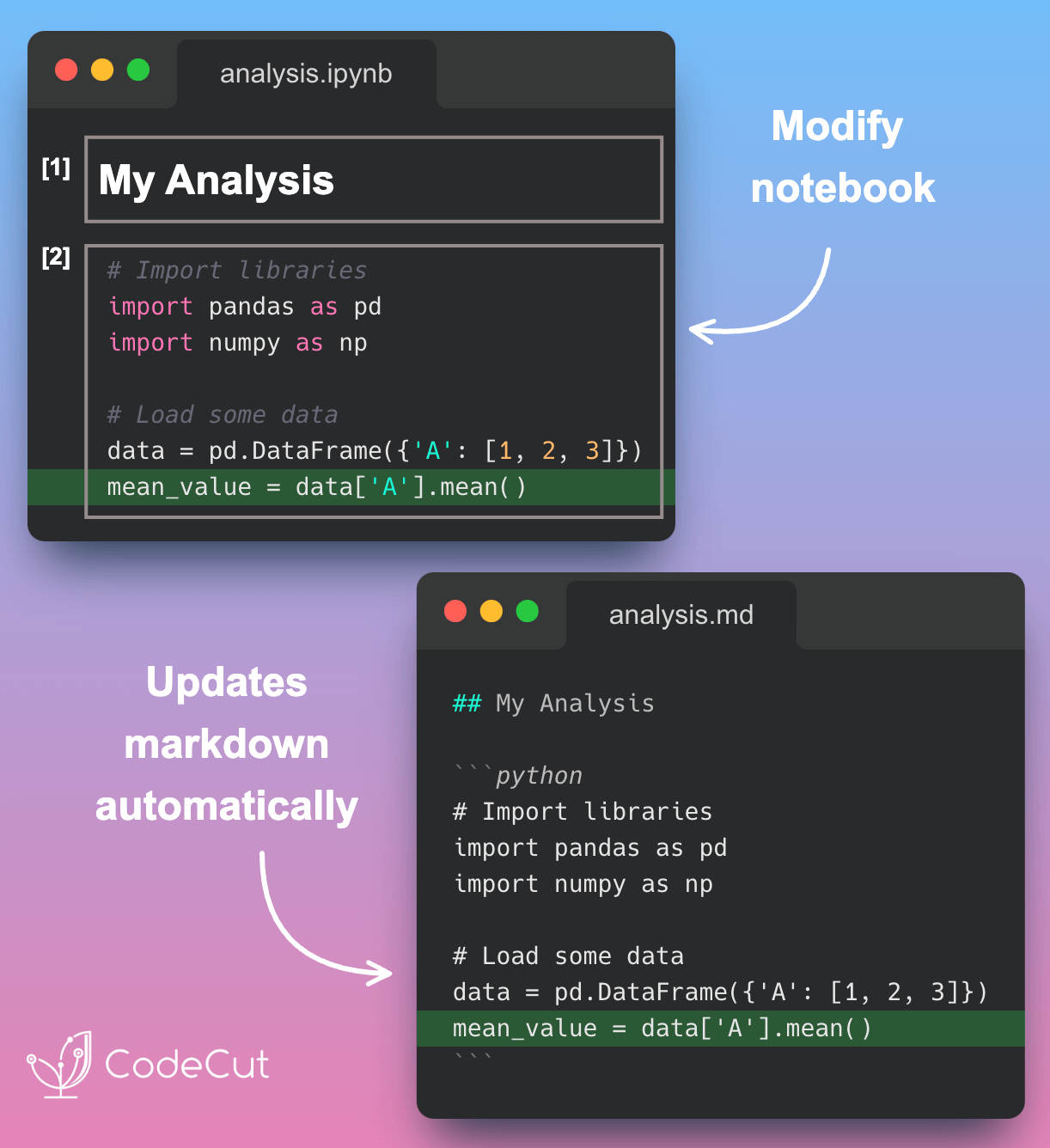
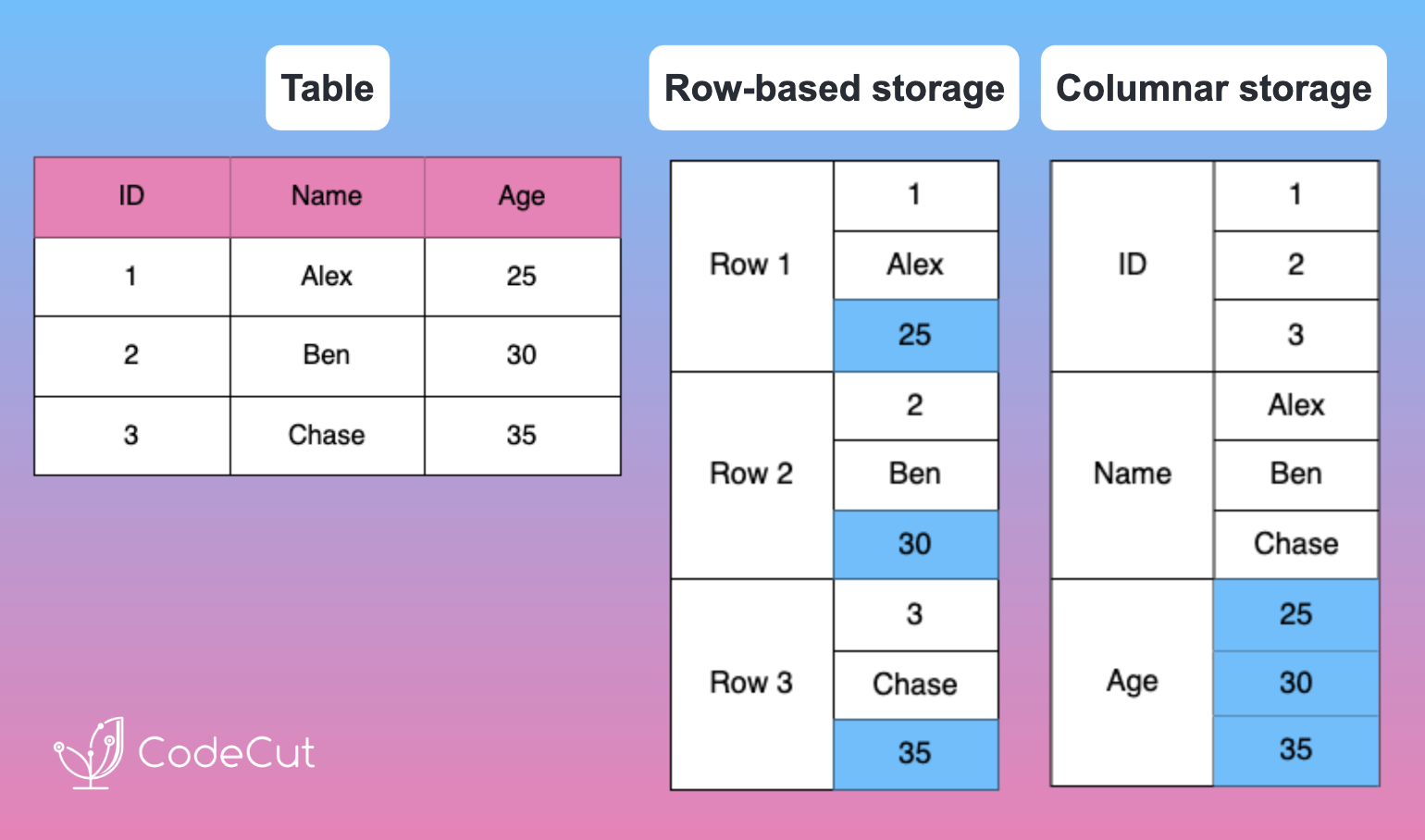
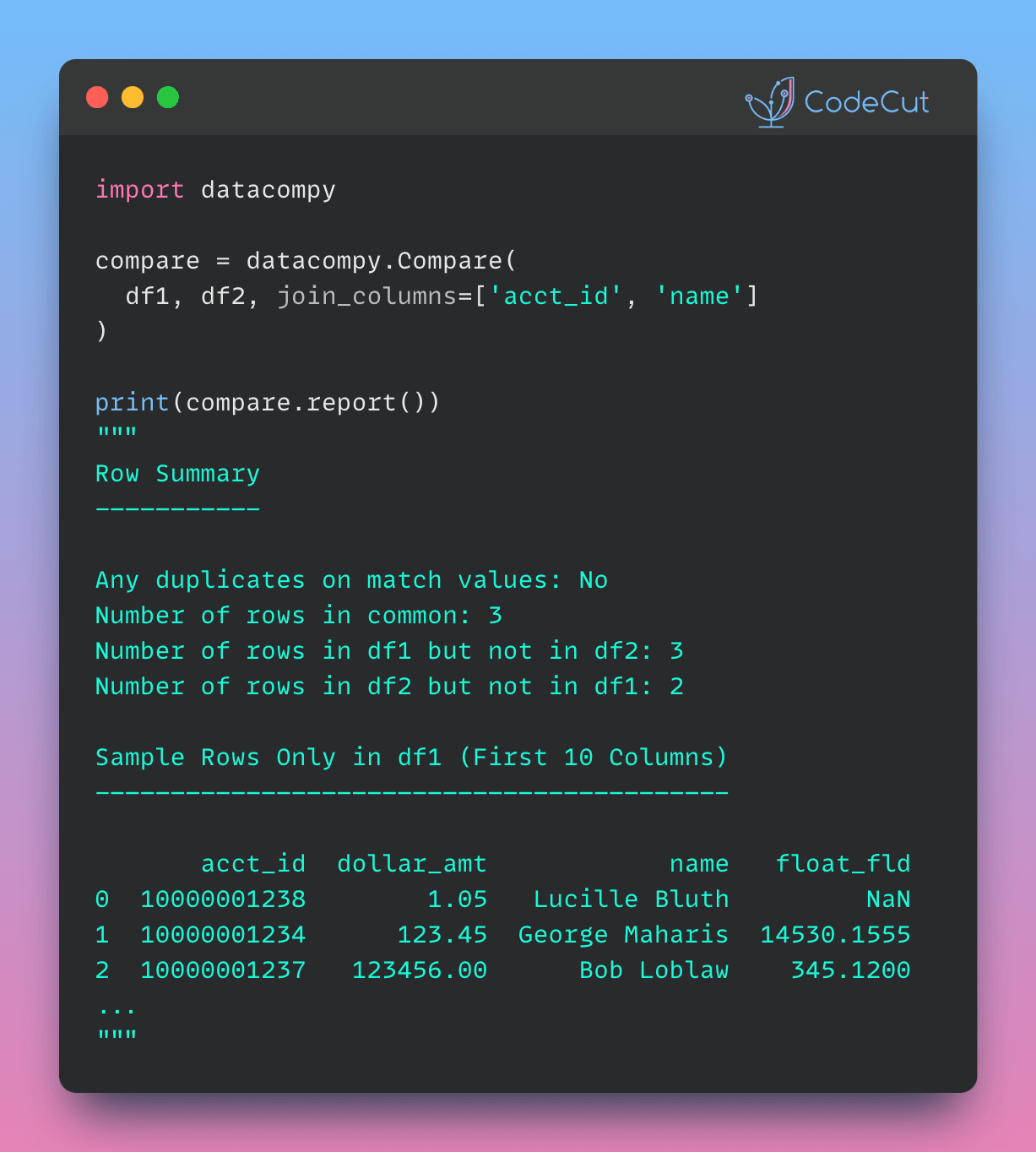
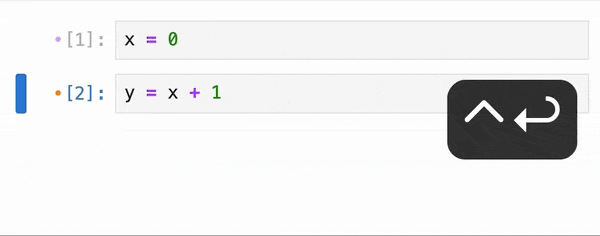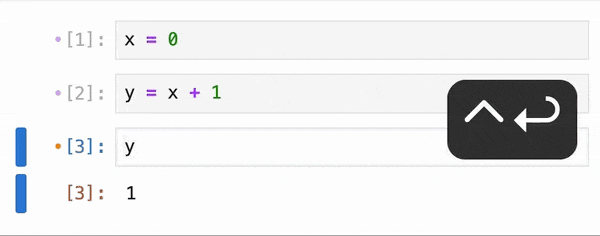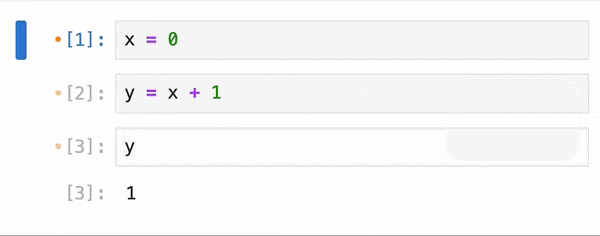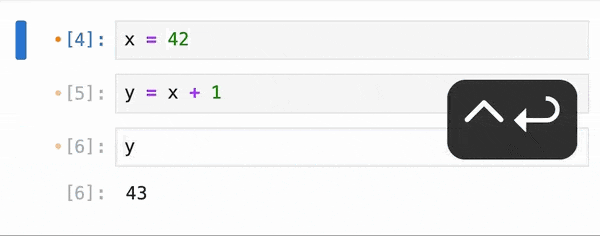
Data Analysis & ManipulationAnalyze DataManage DataFeature EngineerSQLMachine Learning & AIMachine LearningNatural Language ProcessingTime SeriesLLMCode QualityPython TipsPython-UtilitiesCode OptimizationDevOpsTestingGitCommand LineEnvironment ManagementBetter OutputsToolsNumPyPandasPolarsPySparkDelta LakeDuckDBJupyter NotebookVisualization & ReportingDashboardVisualizationWorkflow & AutomationWorkflow AutomationScrape DataX Make PySpark Queries Cleaner with Column Aliasing April 20, 2025 Comparing Join Performance: Pandas vs. Polars April 14, 2025 Automate CSV Parsing with DuckDB’s read_csv April 9, 2025 Update Multiple Columns in Spark 3.3 and Later April 6, 2025 Query Nested Parquet Files Easily Using DuckDB March 30, 2025 Streamline Pattern-Based CSV Processing with DuckDB SQL March 23, 2025 Accelerate DataFrame Operations with Polars Parallel Processing March 19, 2025 Use PySpark UDFs to Make SQL Logic Reusable March 18, 2025 DuckDB: Simplify DataFrame Analysis with Serverless SQL March 9, 2025 Delta Lake: Safely Delete Millions of Records Without Memory Overload March 8, 2025 marimo: Reactive Notebooks for Effortless Visualizations March 7, 2025 Jupytext: Transform Notebooks into Version Control-Friendly Text March 2, 2025 DuckDB: Query Pandas DataFrames Faster with Columnar Storage February 17, 2025 Simplifying Dataset Comparison with Datacompy February 11, 2025 IPyflow: Automatic Dependency Tracking in Jupyter Notebooks February 2, 2025 « Previous Page1 Page2 Page3 Page4 Page5 Next »