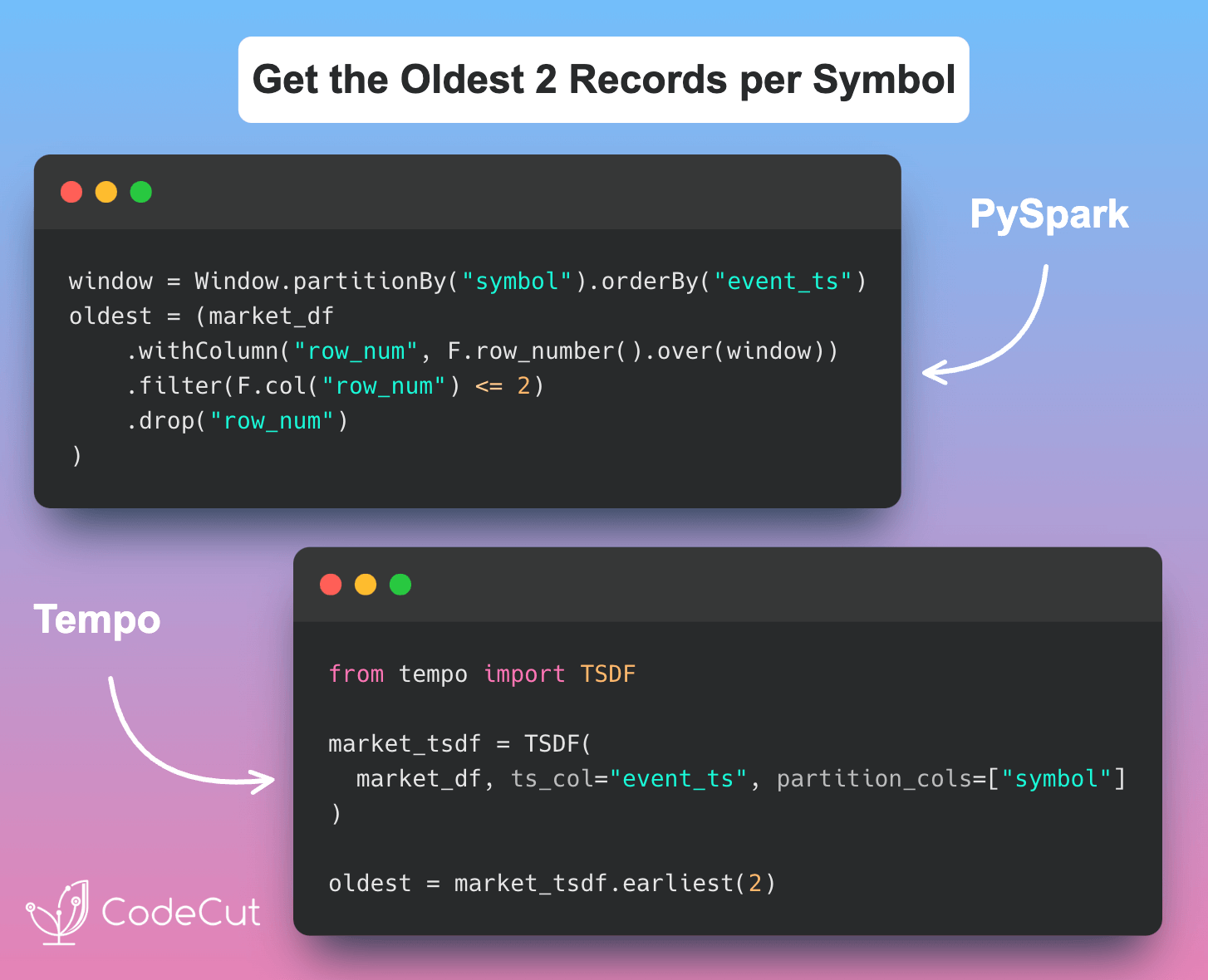
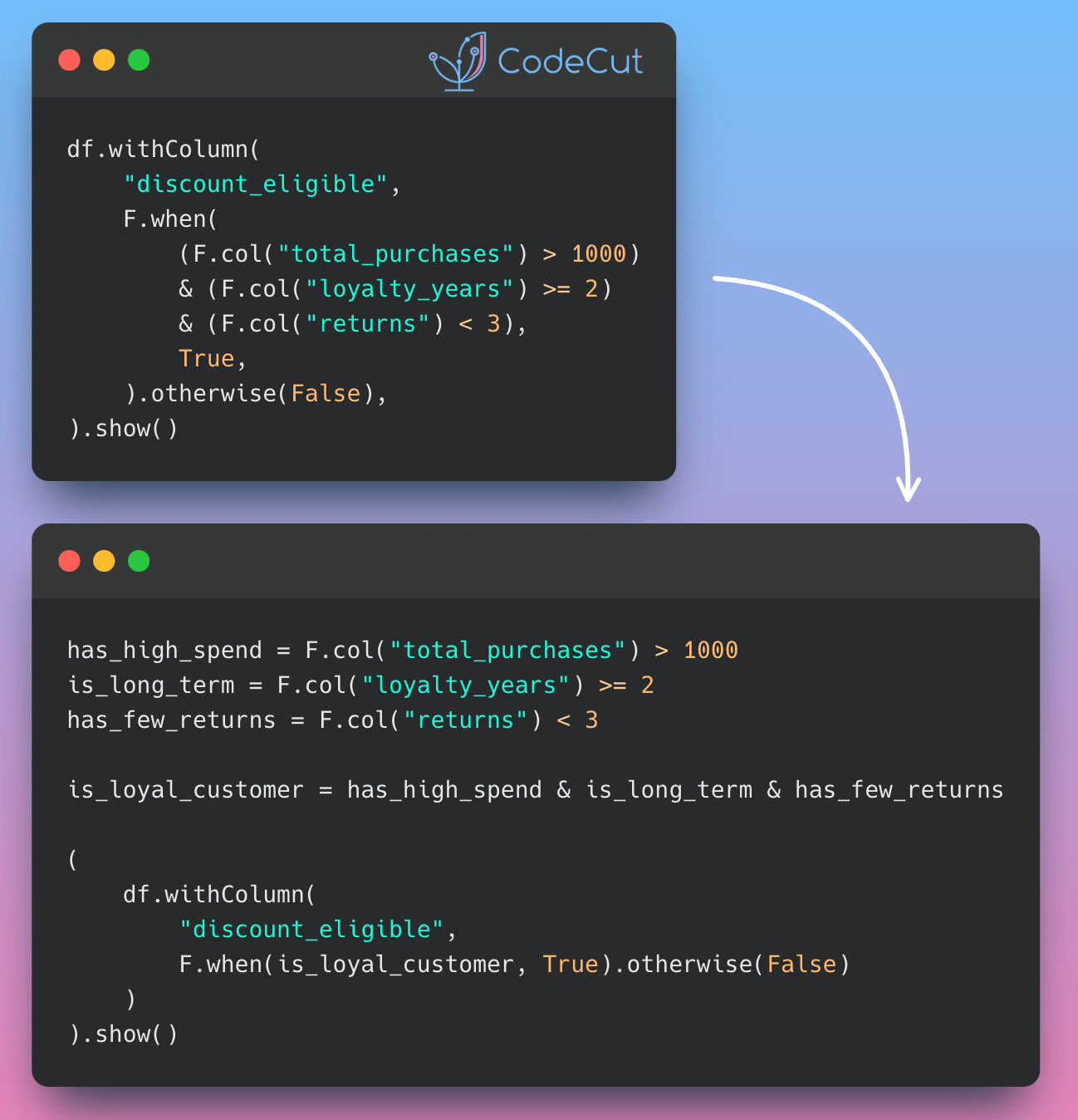
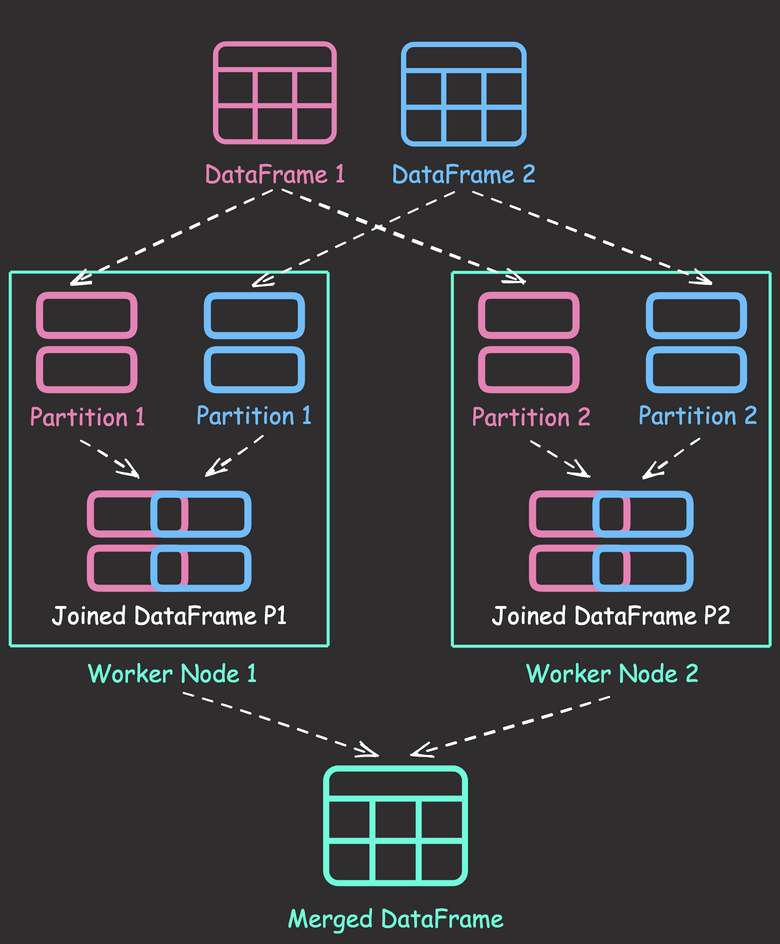
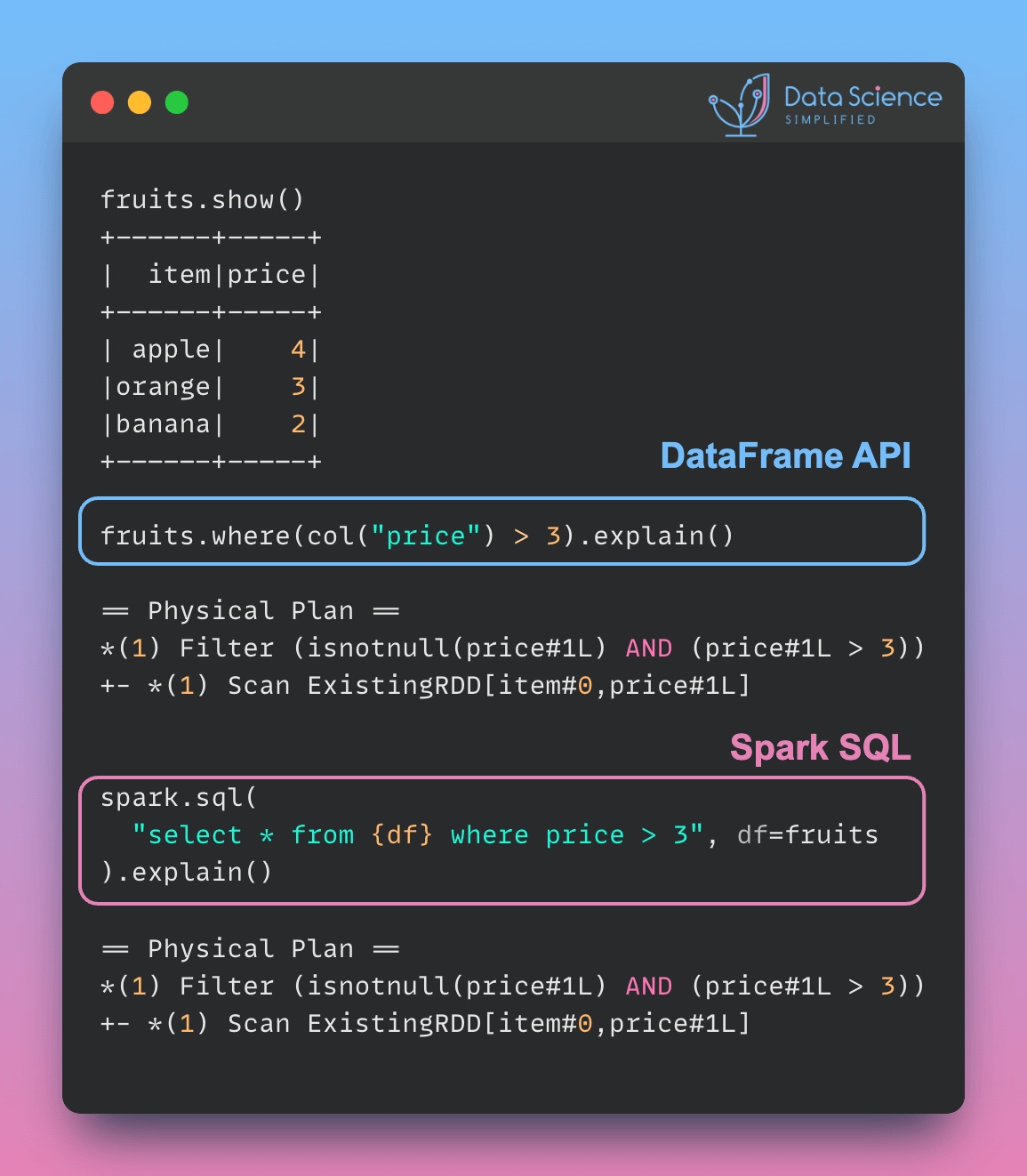
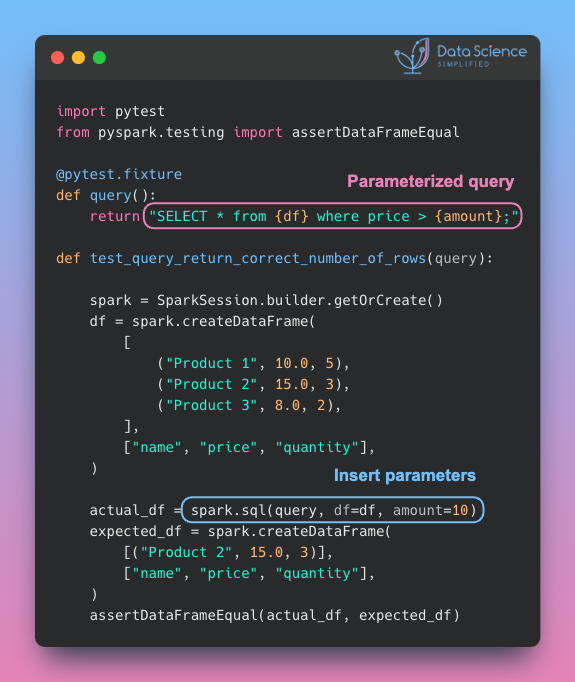
Data Analysis & ManipulationAnalyze DataManage DataFeature EngineerSQLMachine Learning & AIMachine LearningNatural Language ProcessingTime SeriesLLMCode QualityPython TipsPython-UtilitiesCode OptimizationDevOpsTestingGitCommand LineEnvironment ManagementBetter OutputsToolsNumPyPandasPolarsPySparkDelta LakeDuckDBJupyter NotebookVisualization & ReportingDashboardVisualizationWorkflow & AutomationWorkflow AutomationScrape DataX Make PySpark Queries Cleaner with Column Aliasing April 20, 2025 Update Multiple Columns in Spark 3.3 and Later April 6, 2025 Use PySpark UDFs to Make SQL Logic Reusable March 18, 2025 Optimizing PySpark Queries with Nested Data Structures January 9, 2025 Best Practices for PySpark DataFrame Comparison Testing December 22, 2024 Tempo: Simplified Time Series Analysis in PySpark December 5, 2024 Transform Single Inputs into Tables Using PySpark UDTFs November 24, 2024 PySpark Best Practices: Simplifying Logical Chain Conditions November 9, 2024 3 Powerful Ways to Create PySpark DataFrames September 13, 2024 PySpark DataFrame Transformations: select vs withColumn September 2, 2024 Distributed Data Joining with Shuffle Joins in PySpark July 15, 2024 Enhance Code Modularity and Reusability with Temporary Views in PySpark July 8, 2024 Optimizing PySpark Queries: DataFrame API or SQL? June 24, 2024 Vectorized Operations in PySpark: pandas_udf vs Standard UDF June 10, 2024 Simplify Unit Testing of SQL Queries with PySpark May 13, 2024 « Previous Page1 Page2 Next »