🤝 COLLABORATION
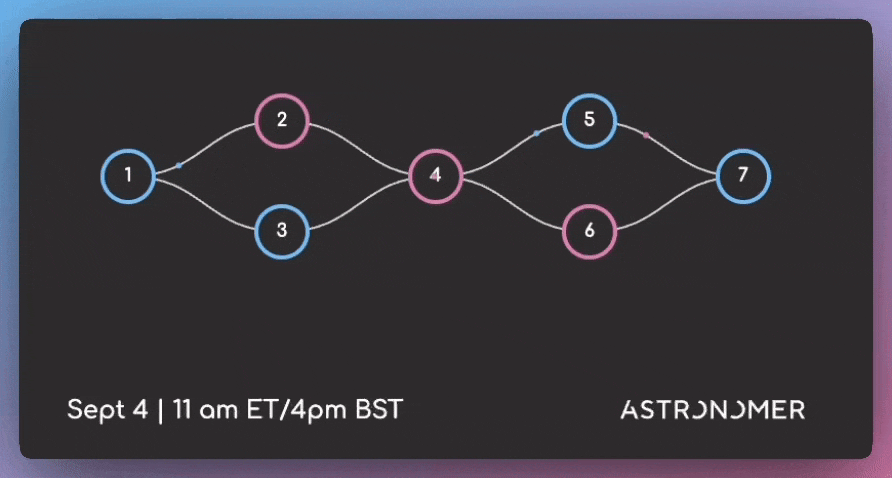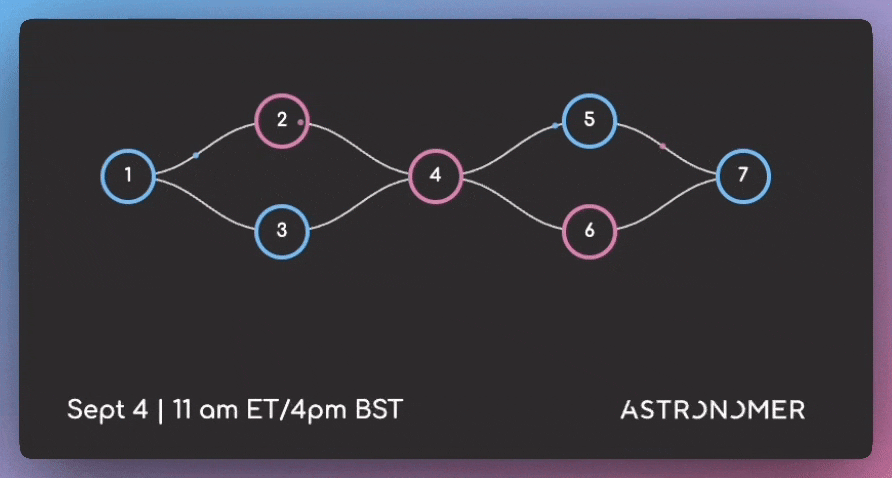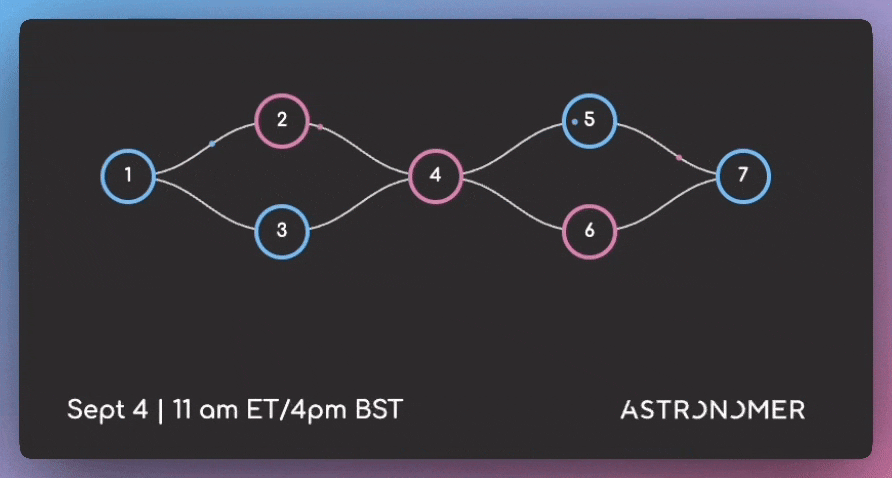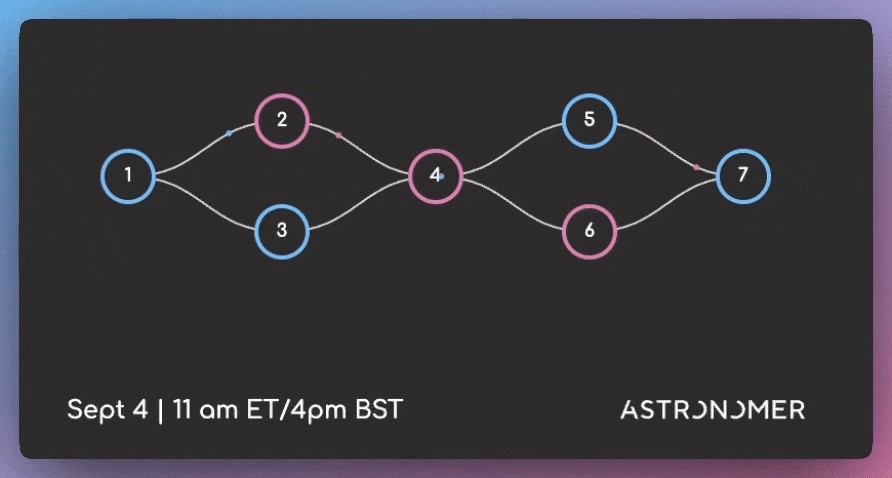
How to write better DAGs in Airflow
DAGs (Directed Acyclic Graphs) are Airflow’s workflow definition format. They specify how data tasks connect and execute in sequence.
Well-designed DAGs handle edge cases, scale with data volume changes, and remain maintainable as your pipeline complexity grows.
What you’ll learn:
- Design DAGs that are easier to read, test, and maintain
- Make your pipelines adapt to your data at runtime with dynamic task mapping
- Avoid common pitfalls that can cause performance issues
- Create data-aware pipelines with XComs and event-driven scheduling
- Learn proven DAG writing best practices including Airflow 3’s latest features
This covers practical patterns for building production-ready workflows that handle failures gracefully and scale with your data infrastructure needs.
Speakers:
- Kenten Danas – Senior Manager, Developer Relations at Astronomer
- Tamara Fingerlin – Developer Advocate at Astronomer
📅 Today’s Picks
Secure Database Queries with DuckDB Parameters
Problem
F-strings create SQL injection vulnerabilities by inserting values directly into queries.
Solution
DuckDB’s parameterized queries use placeholders to safely pass parameters and prevent SQL injection attacks.
Other key features of DuckDB:
- In-Process Analytics – No external database needed
- Fast Performance – Columnar storage for speed
- Zero Setup – Works instantly in Python
- DataFrame Integration – Native pandas support
Build Semantic Text Matching with Sentence Transformers

Problem
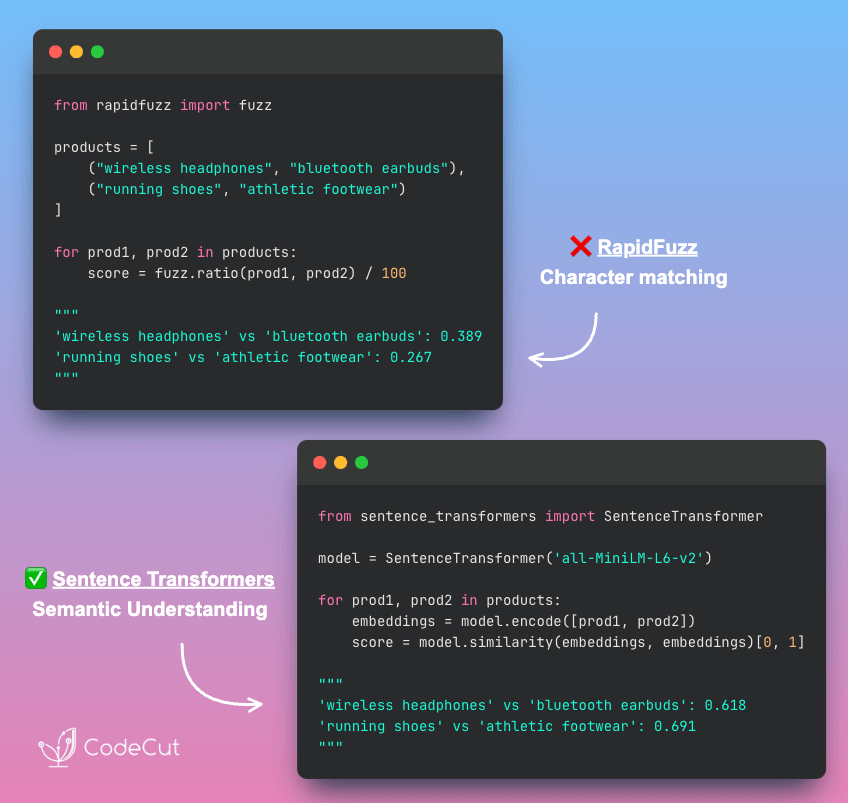
RapidFuzz, which I introduced in my previous post, excels at lightning-fast string matching.
However, it cannot understand semantic relationships. It scores ‘running shoes’ vs ‘athletic footwear’ at only 0.267 despite describing similar product categories.
RapidFuzz compares characters, not meaning, so different words describing identical concepts get low scores.
Solution
Sentence Transformers comprehends conceptual similarity by analyzing word meanings.
Sentence Transformers follows this process:
- Creates embedding vectors that represent word concepts
- Similar meanings produce similar embedding patterns
- Compares these concept embeddings to identify semantically similar text
- Recognizes synonyms and related terminology automatically
☕️ Weekly Finds
tenacity [Testing & Reliability] – Apache 2.0 licensed general-purpose retrying library for Python to simplify adding retry behavior to just about anything
ParadeDB [Database & Search] – Modern Elasticsearch alternative built on Postgres for real-time, update-heavy workloads with full-text search capabilities
responses [Testing & Mocking] – Utility library for mocking out the Python Requests library, making it easy to test HTTP API interactions
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.