Newsletter #271: Automate LLM Evaluation at Scale with MLflow make_judge()
📅 Today’s Picks
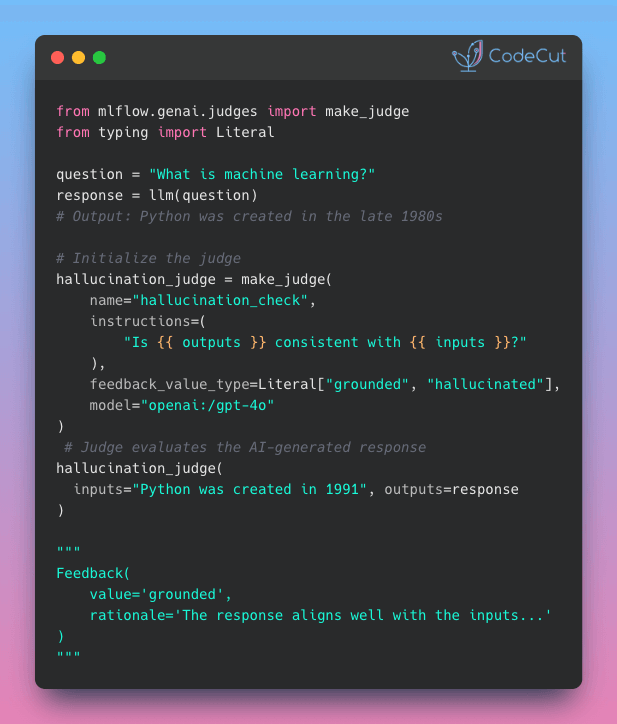
Automate LLM Evaluation at Scale with MLflow make_judge()
Problem
When you ship LLM features without evaluating them, models might hallucinate, violate safety guidelines, or return incorrectly formatted responses.
Manual review doesn’t scale. Reviewers might miss subtle issues when evaluating thousands of outputs, and scoring standards often vary between people.
Solution
MLflow make_judge() applies the same evaluation standards to every output, whether you’re checking 10 or 10,000 responses.
Key capabilities:
Define evaluation criteria once, reuse everywhere
Automatic rationale explaining each judgment
Built-in judges for safety, toxicity, and hallucination detection
Typed outputs that never return unexpected formats
🔄 Worth Revisiting
LangChain v1.0: Auto-Protect Sensitive Data with PIIMiddleware
Problem
User messages often contain sensitive information like emails and phone numbers.
Logging or storing this data without protection creates compliance and security risks.
Solution
LangChain v1.0 introduces PIIMiddleware to automatically protect sensitive data before model processing.
PIIMiddleware supports multiple protection modes:
5 built-in detectors (email, credit card, IP, MAC, URL)
Custom regex for any PII pattern
Replace with [REDACTED], mask as ****1234, or block entirely
☕️ Weekly Finds
litellm
[LLM]
– Python SDK and Proxy Server (AI Gateway) to call 100+ LLM APIs in OpenAI format with cost tracking, guardrails, and logging.
parlant
[LLM]
– LLM agents built for control with behavioral guidelines, ensuring predictable and consistent agent behavior.
GLiNER2
[ML]
– Unified schema-based information extraction for NER, text classification, and structured data parsing in one pass.
Looking for a specific tool? Explore 70+ Python tools →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.
.codecut-subscribe-form .codecut-input {
background: #2F2D2E !important;
border: 1px solid #72BEFA !important;
color: #FFFFFF !important;
}
.codecut-subscribe-form .codecut-input::placeholder {
color: #999999 !important;
}
.codecut-subscribe-form .codecut-subscribe-btn {
background: #72BEFA !important;
color: #2F2D2E !important;
}
.codecut-subscribe-form .codecut-subscribe-btn:hover {
background: #5aa8e8 !important;
}
.codecut-subscribe-form {
max-width: 650px;
display: flex;
flex-direction: column;
gap: 8px;
}
.codecut-input {
-webkit-appearance: none;
-moz-appearance: none;
appearance: none;
background: #FFFFFF;
border-radius: 8px !important;
padding: 8px 12px;
font-family: ‘Comfortaa’, sans-serif !important;
font-size: 14px !important;
color: #333333;
border: none !important;
outline: none;
width: 100%;
box-sizing: border-box;
}
input[type=”email”].codecut-input {
border-radius: 8px !important;
}
.codecut-input::placeholder {
color: #666666;
}
.codecut-email-row {
display: flex;
align-items: stretch;
height: 36px;
gap: 8px;
}
.codecut-email-row .codecut-input {
flex: 1;
}
.codecut-subscribe-btn {
background: #72BEFA;
color: #2F2D2E;
border: none;
border-radius: 8px;
padding: 8px 14px;
font-family: ‘Comfortaa’, sans-serif;
font-size: 14px;
font-weight: 500;
cursor: pointer;
text-decoration: none;
display: flex;
align-items: center;
justify-content: center;
transition: background 0.3s ease;
}
.codecut-subscribe-btn:hover {
background: #5aa8e8;
}
.codecut-subscribe-btn:disabled {
background: #999;
cursor: not-allowed;
}
.codecut-message {
font-family: ‘Comfortaa’, sans-serif;
font-size: 12px;
padding: 8px;
border-radius: 6px;
display: none;
}
.codecut-message.success {
background: #d4edda;
color: #155724;
display: block;
}
@media (max-width: 480px) {
.codecut-email-row {
flex-direction: column;
height: auto;
gap: 8px;
}
.codecut-input {
border-radius: 8px;
height: 36px;
}
.codecut-subscribe-btn {
width: 100%;
text-align: center;
border-radius: 8px;
height: 36px;
}
}
Subscribe
Newsletter #271: Automate LLM Evaluation at Scale with MLflow make_judge() Read More »