Accelerate DataFrame Operations with Polars Parallel Processing
Motivation
Data engineers frequently need to process multiple related datasets together. When using pandas, each DataFrame is typically processed sequentially, which can be inefficient and time-consuming.
Here’s a common inefficient approach with pandas:
import numpy as np
import pandas as pd
def add_metric_scaled(df, metric_column):
return df.assign(
metric_scaled=lambda x: (x[metric_column] – x[metric_column].mean())
/ x[metric_column].std()
)
# Create the first DataFrame with purchases data
df1 = pd.DataFrame(
{"user_id": range(1000), "purchases": np.random.randint(1, 100, 1000)}
)
df1 = add_metric_scaled(df1, "purchases")
# Create the second DataFrame with clicks data
df2 = pd.DataFrame({"user_id": range(1000), "clicks": np.random.randint(1, 500, 1000)})
df2 = add_metric_scaled(df2, "clicks")
# Create the third DataFrame with page_views data
df3 = pd.DataFrame(
{"user_id": range(1000), "page_views": np.random.randint(1, 1000, 1000)}
)
df3 = add_metric_scaled(df3, "page_views")
This sequential approach has several drawbacks:
Each DataFrame is processed one after another
CPU cores remain underutilized
Total processing time increases linearly with the number of DataFrames
Memory usage isn’t optimized
Understanding Parallel DataFrame Collection
Modern CPUs have multiple cores that can process data simultaneously. While pandas operations are primarily single-threaded, Polars is designed for parallel execution, allowing multiple DataFrame operations to run concurrently.
Introduction to Polars
This article covers how to speed up your data processing workflows by taking advantage of Polars’ ability to execute operations in parallel across multiple DataFrames. If you’re new to Polars or considering transitioning from Pandas, this detailed comparison article Polars vs. Pandas: A Fast, Multi-Core Alternative for DataFrames provides valuable insights into the advantages and differences between the two libraries.Polars is a high-performance DataFrame library that excels at parallel processing. Install it using:
pip install polars
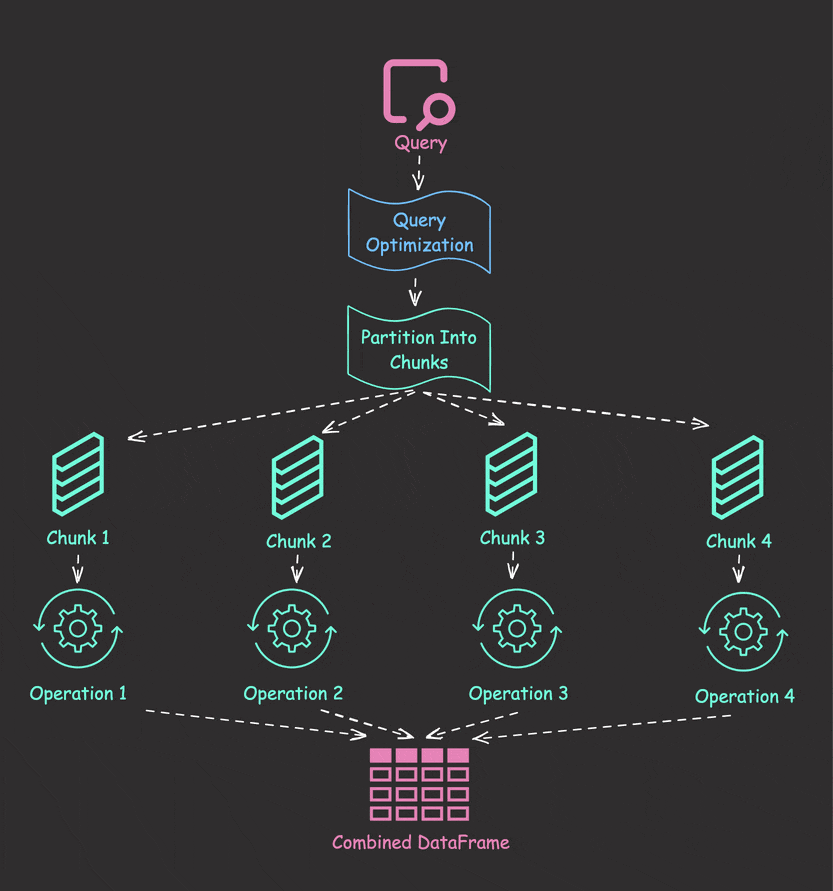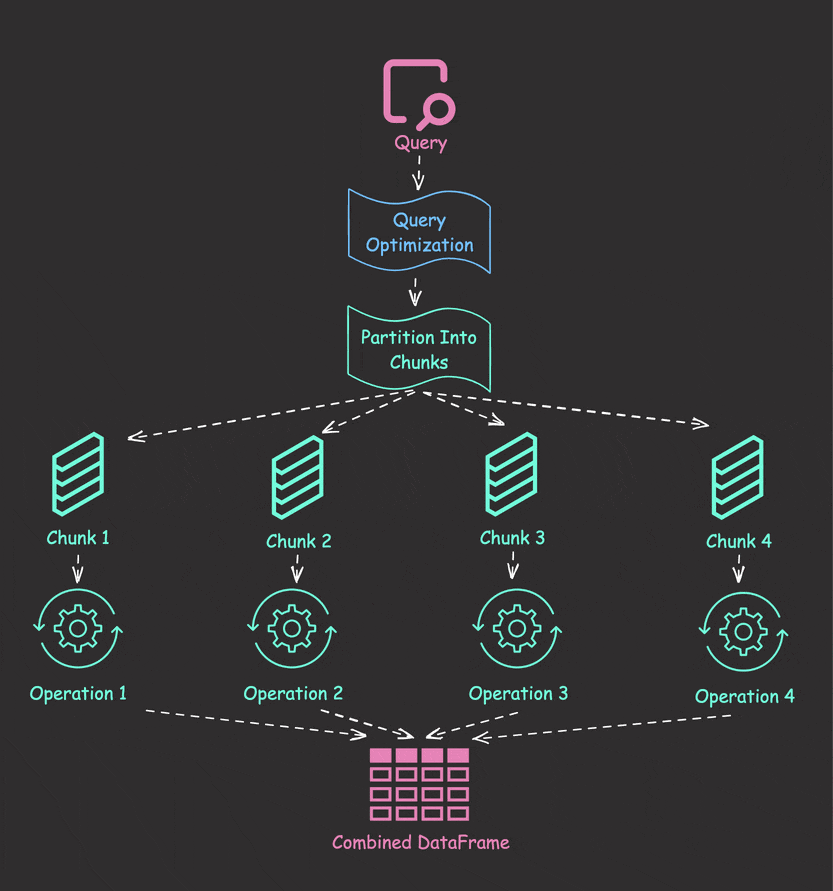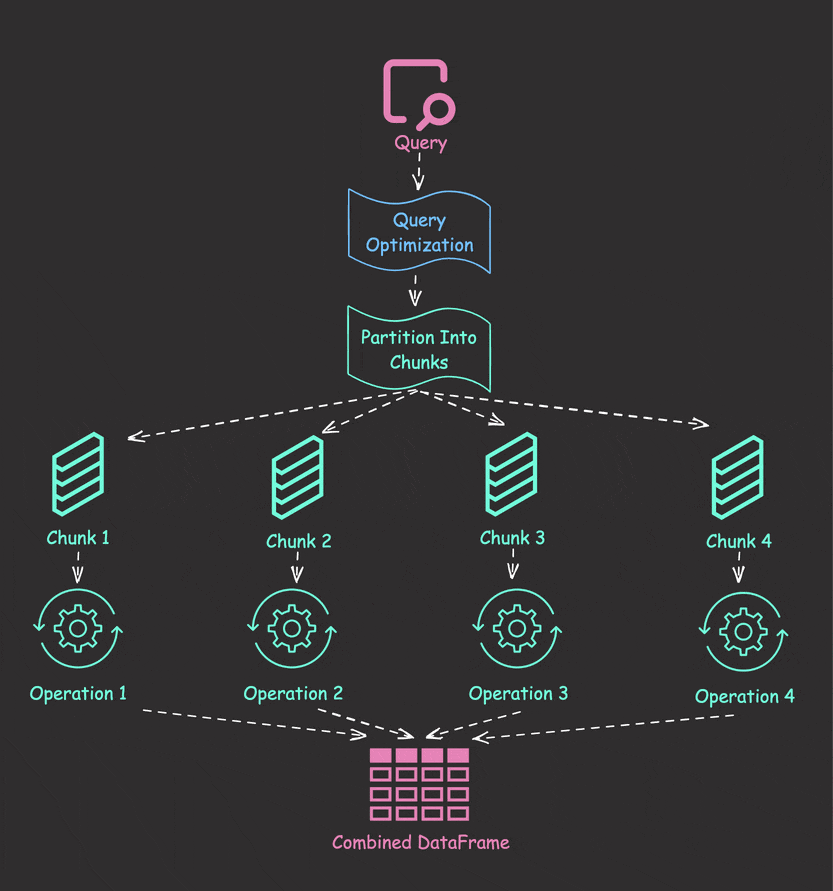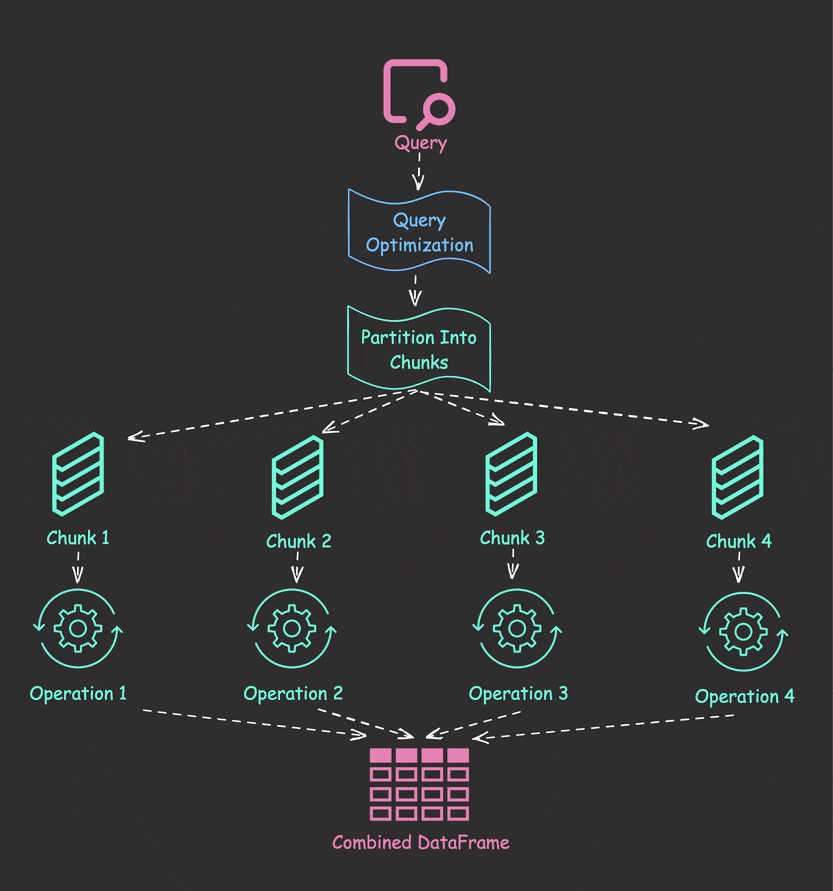
Parallel Collection with collect_all
Let’s solve the sequential processing problem using Polars’ collect_all:
import numpy as np
import polars as pl
def add_metric_scaled(df, metric_column):
return df.with_columns(
[
(pl.col(metric_column) – pl.col(metric_column).mean())
/ pl.col(metric_column).std().alias("metric_scaled")
]
)
# Create the first LazyFrame with purchases data
lazy_frame1 = add_metric_scaled(
pl.DataFrame(
{"user_id": range(1000), "purchases": np.random.randint(1, 100, 1000)}
).lazy(),
"purchases",
)
# Create the second LazyFrame with clicks data
lazy_frame2 = add_metric_scaled(
pl.DataFrame(
{"user_id": range(1000), "clicks": np.random.randint(1, 500, 1000)}
).lazy(),
"clicks",
)
# Create the third LazyFrame with page_views data
lazy_frame3 = add_metric_scaled(
pl.DataFrame(
{"user_id": range(1000), "page_views": np.random.randint(1, 1000, 1000)}
).lazy(),
"page_views",
)
# Process all frames in parallel
results = pl.collect_all([lazy_frame1, lazy_frame2, lazy_frame3])
print(results)
Output:
[shape: (1_000, 2)
┌─────────┬───────────┐
│ user_id ┆ purchases │
│ — ┆ — │
│ i64 ┆ f64 │
╞═════════╪═══════════╡
│ 0 ┆ -1.553524 │
│ 1 ┆ -0.528352 │
│ 2 ┆ -1.200017 │
│ 3 ┆ -1.093965 │
│ 4 ┆ -1.412121 │
│ … ┆ … │
│ 995 ┆ 1.027081 │
│ 996 ┆ -1.553524 │
│ 997 ┆ -0.669755 │
│ 998 ┆ -0.705106 │
│ 999 ┆ 0.03726 │
└─────────┴───────────┘, shape: (1_000, 2)
┌─────────┬───────────┐
│ user_id ┆ clicks │
│ — ┆ — │
│ i64 ┆ f64 │
╞═════════╪═══════════╡
│ 0 ┆ -1.32932 │
│ 1 ┆ 1.250184 │
│ 2 ┆ -0.560815 │
│ 3 ┆ 0.047306 │
│ 4 ┆ 1.31701 │
│ … ┆ … │
│ 995 ┆ 1.611047 │
│ 996 ┆ 1.169992 │
│ 997 ┆ 0.354708 │
│ 998 ┆ -0.914995 │
│ 999 ┆ 1.136579 │
└─────────┴───────────┘, shape: (1_000, 2)
┌─────────┬────────────┐
│ user_id ┆ page_views │
│ — ┆ — │
│ i64 ┆ f64 │
╞═════════╪════════════╡
│ 0 ┆ 0.042274 │
│ 1 ┆ 1.50377 │
│ 2 ┆ -0.368771 │
│ 3 ┆ -1.72487 │
│ 4 ┆ -1.742436 │
│ … ┆ … │
│ 995 ┆ -0.814949 │
│ 996 ┆ 1.531876 │
│ 997 ┆ -1.728383 │
│ 998 ┆ -0.249322 │
│ 999 ┆ 0.741403 │
└─────────┴────────────┘]
The benefits include:
All DataFrames are processed simultaneously
Better CPU utilization through parallel processing
Reduced total processing time
Optimized memory usage through Polars’ efficient memory management
Conclusion
Polars’ collect_all function provides a significant performance improvement over sequential pandas processing by executing multiple DataFrame computations in parallel. This approach is particularly valuable when dealing with multiple related datasets that need similar transformations applied.
.stk-b237d21-container{background-color:var(–ast-global-color-0) !important;}.stk-b237d21-container:before{background-color:var(–ast-global-color-0) !important;}.stk-b237d21 .stk-block-call-to-action__content{max-width:700px !important;min-width:auto !important;}
.stk-3e42139 .stk-block-heading__text{color:var(–ast-global-color-4) !important;font-family:”Comfortaa”, Sans-serif !important;}Want the full walkthrough?
.stk-e915396 .stk-block-text__text{color:var(–ast-global-color-4) !important;}Check out our in-depth guide on Polars vs Pandas: A Fast, Multi-Core Alternative for DataFrames
.stk-c77f1ca {border-top-left-radius:1px !important;border-top-right-radius:1px !important;border-bottom-right-radius:1px !important;border-bottom-left-radius:1px !important;overflow:hidden !important;border-style:solid !important;border-top-width:1px !important;border-right-width:1px !important;border-bottom-width:1px !important;border-left-width:1px !important;}.stk-c77f1ca .stk-button{min-height:0px !important;padding-top:18px !important;padding-right:29px !important;padding-bottom:18px !important;padding-left:29px !important;background:var(–ast-global-color-1) !important;border-top-left-radius:13px !important;border-top-right-radius:13px !important;border-bottom-right-radius:13px !important;border-bottom-left-radius:13px !important;}.stk-c77f1ca .stk-button:before{border-style:solid !important;border-color:var(–ast-global-color-2) !important;border-top-width:1px !important;border-right-width:1px !important;border-bottom-width:1px !important;border-left-width:1px !important;}.stk-c77f1ca .stk-button .stk–inner-svg svg:last-child, .stk-c77f1ca .stk-button .stk–inner-svg svg:last-child :is(g, path, rect, polygon, ellipse){fill:var(–ast-global-color-1) !important;}.stk-c77f1ca .stk-button__inner-text{font-size:17px !important;}@media screen and (max-width: 1023px){.stk-c77f1ca .stk-button__inner-text{font-size:17px !important;}}View the in-depth guide
Accelerate DataFrame Operations with Polars Parallel Processing Read More »