Table of Contents
Introduction
Tool Selection Criteria
Regular Expressions: Pattern-Based Recognition
spaCy: Production-Grade NER
GLiNER: Zero-Shot Entity Extraction
langextract: AI-Powered Extraction with Source Grounding
Conclusion
Introduction
Unstructured text often hides rich structured information. For instance, financial reports contain company names, monetary figures, executives, dates, and locations used for competitive analysis and executive tracking.
However, extracting these entities manually is time-consuming and error-prone.
A better approach is to use an automated approach to extract the entities. There are several tools that can be used to extract the entities. In this article, we will compare four tools: regular expressions, spaCy, GLiNER, and langextract.
We will start with a straightforward approach then gradually move to more advanced approaches depending on the complexity of the entities.
Interactive Course: Master entity extraction with spaCy and LLMs through hands-on exercises in our interactive entity extraction course.
Tool Selection Criteria
Select your entity extraction method based on these core differentiators:
Regular Expressions: Pattern Matching
Strength: Microsecond latency with zero dependencies
Best for: Structured data with consistent formats (dates, IDs, phone numbers)
spaCy: Production-Ready NER
Strength: 10,000+ entities/second with enterprise reliability
Best for: Standard business entities in high-volume production systems
GLiNER: Custom Entity Flexibility
Strength: Zero-shot custom entity recognition without training data
Best for: Dynamic entity requirements and specialized domains
langextract: Context-Aware AI
Strength: Finds entity relationships (CEO → company) with source citations for verification
Best for: Document analysis requiring transparent, traceable entity extraction
Regular Expressions: Pattern-Based Recognition
Regular expressions excel at extracting entities with consistent formats. Financial documents contain structured patterns perfect for regex recognition. Let’s see how regular expressions can extract these entities.
💡 Tip: While regex is powerful for structured patterns, complex expressions can be hard to read and maintain. For a more intuitive approach, check out PRegEx: Write Human-Readable Regular Expressions in Python to build regex patterns with readable Python syntax.
First, let’s define the earnings report that we will use for extraction:
import re
from pathlib import Path
# Define the earnings report locally for this section
earning_report = """
Apple Inc. (NASDAQ: AAPL) reported third quarter revenue of $81.4 billion,
up 2% year over year. CEO Tim Cook stated that Services revenue reached
a new all-time high of $21.2 billion. The company's board of directors
declared a cash dividend of $0.24 per share.
CFO Luca Maestri mentioned that iPhone revenue was $39.3 billion for
the quarter ending June 30, 2023. The company expects total revenue
between $89 billion and $93 billion for the fourth quarter.
Apple's Cupertino headquarters announced the acquisition of AI startup
WaveOne for an undisclosed amount. The deal is expected to close in
Q4 2023, pending regulatory approval from the SEC.
"""
Define the extraction functions, including:
Financial amounts ($1.2 billion, $39.3 million)
Dates (June 30, 2023)
Stock symbols (NASDAQ: AAPL, NYSE: MSFT)
Percentages (2%, 15%)
Quarters (Q3 2023, Q4 2023)
def extract_financial_amounts(text):
"""Extract financial amounts like $1.2 billion, $39.3 million."""
financial_pattern = r"\$(?:\d{1,3}(?:,\d{3})+|\d+)(?:\.[0-9]+)?(?:\s*(?:billion|million|trillion))?"
return re.findall(financial_pattern, text, re.IGNORECASE)
def extract_dates(text):
"""Extract formatted dates like June 30, 2023."""
date_pattern = r"\b(?:January|February|March|April|May|June|July|August|September|October|November|December)\s+\d{1,2},\s+\d{4}"
return re.findall(date_pattern, text)
def extract_stock_symbols(text):
"""Extract stock symbols like NASDAQ: AAPL, NYSE: MSFT."""
stock_pattern = r"\b(?:NASDAQ|NYSE|NYSEARCA):\s*[A-Z]{2,5}\b"
return re.findall(stock_pattern, text)
def extract_percentages(text):
"""Extract percentage values like 2%, 15.5%."""
percentage_pattern = r"\b\d+(?:\.\d+)?%"
return re.findall(percentage_pattern, text)
def extract_quarters(text):
"""Extract quarterly periods like Q1 2023, Q4 2024."""
quarter_pattern = r"\b(Q[1-4]\s+\d{4})\b"
return re.findall(quarter_pattern, text)
def extract_entities_regex(text):
"""Extract business entities using regular expressions."""
entities = {
"financial_amounts": extract_financial_amounts(text),
"dates": extract_dates(text),
"stock_symbols": extract_stock_symbols(text),
"percentages": extract_percentages(text),
"quarters": extract_quarters(text),
}
return entities
Extract entities:
# Extract entities
regex_entities = extract_entities_regex(earning_report)
print("Regular Expression Entity Extraction:")
for entity_type, values in regex_entities.items():
if values:
print(f" {entity_type}: {values}")
Output:
Regular Expression Entity Extraction:
financial_amounts: ['$81.4 billion', '$21.2 billion', '$39.3 billion', '$89 billion', '$93 billion']
dates: ['June 30, 2023']
stock_symbols: ['AAPL']
percentages: ['2%']
quarters: ['Q4 2023']
Regex reliably captures structured patterns such as financial amounts, dates, stock symbols, percentages, and quarters. However, it only matches numeric quarter formats like “Q4 2023” and misses textual forms such as “third quarter” unless additional exact-match patterns are added.
spaCy: Production-Grade NER
Regex handles fixed formats, but for context-driven entities we use spaCy. With pretrained pipelines, spaCy’s NER identifies and labels types such as PERSON, ORG, MONEY, DATE, and PERCENT.
Let’s start by installing spaCy and downloading a pre-trained English model:
pip install spacy
python -m spacy download en_core_web_sm
First, let’s see how spaCy processes text and identifies entities:
import spacy
# Load the English language model
nlp = spacy.load("en_core_web_sm")
# Process a simple sentence to see how spaCy works
sample_text = "Apple Inc. reported revenue of $81.4 billion with CEO Tim Cook."
doc = nlp(sample_text)
print("Entities found in sample text:")
for ent in doc.ents:
print(f"'{ent.text}' -> {ent.label_} ({ent.label_})")
Output:
Entities found in sample text:
'Apple Inc.' -> ORG (ORG)
'$81.4 billion' -> MONEY (MONEY)
'Tim Cook' -> PERSON (PERSON)
spaCy automatically identified three different entity types from context alone:
Apple Inc. (ORG): Recognized as an organization based on the company suffix and context (subject of “reported”).
$81.4 billion (MONEY): Identified as a monetary value from the currency symbol, number, and magnitude word.
Tim Cook (PERSON): Labeled as a person using proper name patterns, reinforced by nearby role noun “CEO”.
Now let’s build a comprehensive extraction function for our full business document:
from collections import defaultdict
def extract_entities_spacy(text):
"""Extract business entities using spaCy NER with detailed information."""
doc = nlp(text)
entities = defaultdict(list)
for ent in doc.ents:
entities[ent.label_].append(ent.text)
return dict(entities)
Now let’s apply this to our complete business document:
# Define the earnings report locally for this section
earning_report = """
Apple Inc. (NASDAQ: AAPL) reported third quarter revenue of $81.4 billion,
up 2% year over year. CEO Tim Cook stated that Services revenue reached
a new all-time high of $21.2 billion. The company's board of directors
declared a cash dividend of $0.24 per share.
CFO Luca Maestri mentioned that iPhone revenue was $39.3 billion for
the quarter ending June 30, 2023. The company expects total revenue
between $89 billion and $93 billion for the fourth quarter.
Apple's Cupertino headquarters announced the acquisition of AI startup
WaveOne for an undisclosed amount. The deal is expected to close in
Q4 2023, pending regulatory approval from the SEC.
"""
# Extract entities from the full text
spacy_entities = extract_entities_spacy(earning_report)
print("spaCy NER Entity Extraction:")
for entity_type, entities_list in spacy_entities.items():
print(f"\n{entity_type} ({len(entities_list)} found):")
for entity in entities_list:
print(f" {entity}")
Output:
spaCy NER Entity Extraction:
ORG (7 found):
Apple Inc.
NASDAQ
Services
iPhone
Apple
WaveOne
SEC
DATE (4 found):
third quarter
the quarter ending June 30, 2023
the fourth quarter
Q4 2023
MONEY (5 found):
$81.4 billion
$21.2 billion
0.24
$39.3 billion
between $89 billion and $93 billion
PERCENT (1 found):
2%
PERSON (1 found):
Tim Cook
GPE (2 found):
Cupertino
AI
The model correctly identifies key financial entities like revenue figures and dates, but misclassifies some technical terms:
“AI” as GPE (Geopolitical Entity): In the phrase “AI startup WaveOne,” the model treats “AI” as a modifier that could resemble a geographic descriptor, similar to how “Silicon Valley startup” would be parsed
“Services” as ORG: Appearing in “Services revenue reached,” the model lacks context that this refers to Apple’s services division and interprets the capitalized “Services” as a standalone company name
“iPhone” as ORG: Should be classified as a product, but the model sees a capitalized term in a financial context and defaults to organization classification
“WaveOne” as ORG: While technically correct as a startup company, this could also be considered a misclassification if we expect more specific entity types for acquisition targets or startups
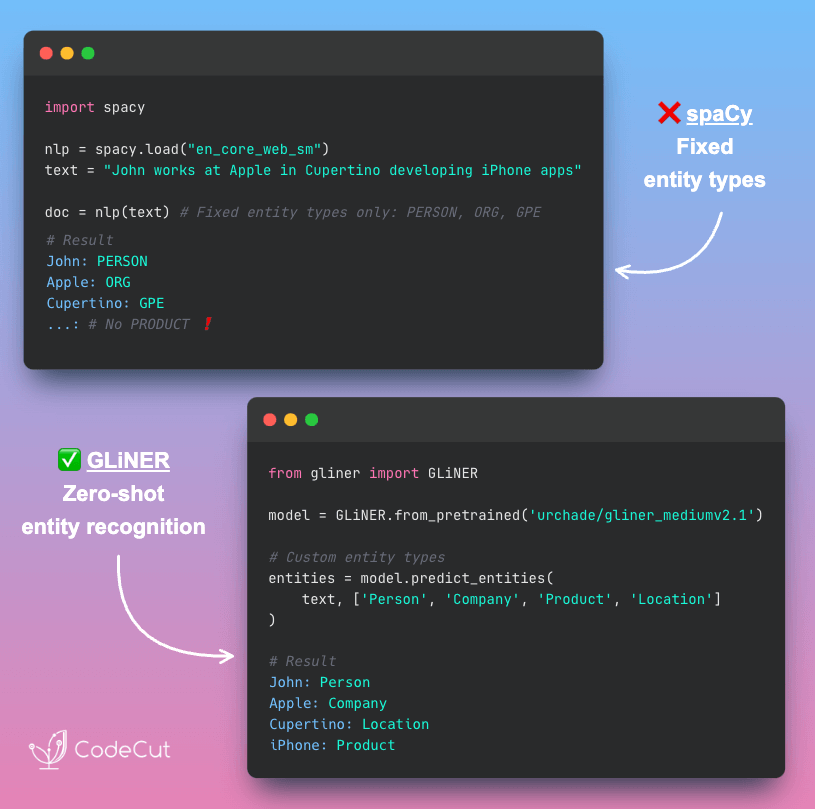
These limitations highlight a fundamental challenge: pre-trained models are constrained by their fixed entity categories and training data.
Business documents require more nuanced classifications, distinguishing between products and companies, or identifying specific business roles like “startup” or “regulatory body.”
📚 For taking your data science projects from prototype to production, check out Production-Ready Data Science.
GLiNER: Zero-Shot Entity Extraction
GLiNER (Generalist and Lightweight Named Entity Recognition) addresses these exact limitations through zero-shot learning. Instead of being locked into predetermined categories like ORG or GPE, GLiNER interprets natural language descriptions.
You can define custom entity types like “startup_company” or “product_name” and GLiNER will find them without any training examples.
Let’s install GLiNER and see how zero-shot entity extraction works:
pip install gliner
First, let’s load the GLiNER model and test it with a simple custom entity type:
from gliner import GLiNER
# Load the pre-trained GLiNER model from Hugging Face
model = GLiNER.from_pretrained("urchade/gliner_mediumv2.1")
# Test with a simple example to understand zero-shot capabilities
test_text = "Apple Inc. CEO Tim Cook announced quarterly revenue of $81.4 billion."
simple_entities = ["technology_company", "executive_role"]
# Extract entities using custom descriptions
entities = model.predict_entities(test_text, simple_entities)
for entity in entities:
print(f"'{entity['text']}' -> {entity['label']} (confidence: {entity['score']:.3f})")
Output:
'Apple Inc.' -> technology_company (confidence: 0.959)
'Tim Cook' -> executive_role (confidence: 0.884)
GLiNER excels at zero-shot extraction by understanding descriptive label names like “technology_company” and “executive_role” without additional training. Next, we define a helper to group results by label with offsets and confidence.
from collections import defaultdict
def extract_entities_gliner(text, entity_types):
"""Extract custom business entities using GLiNER zero-shot learning."""
entities = model.predict_entities(text, entity_types)
grouped_entities = defaultdict(list)
for entity in entities:
grouped_entities[entity['label']].append({
'text': entity['text'],
'start': entity['start'],
'end': entity['end'],
'confidence': round(entity['score'], 3)
})
return dict(grouped_entities)
Now declare the custom business entity types and the input text used for extraction.
business_entities = [
"company",
"executive",
"financial_figure",
"product",
"startup",
"regulatory_body",
"quarter",
"location",
"percentage",
"stock_symbol",
"market_reaction",
]
earning_report = """
Apple Inc. (NASDAQ: AAPL) reported third quarter revenue of $81.4 billion,
up 2% year over year. CEO Tim Cook stated that Services revenue reached
a new all-time high of $21.2 billion. The company's board of directors
declared a cash dividend of $0.24 per share.
CFO Luca Maestri mentioned that iPhone revenue was $39.3 billion for
the quarter ending June 30, 2023. The company expects total revenue
between $89 billion and $93 billion for the fourth quarter.
Apple's Cupertino headquarters announced the acquisition of AI startup
WaveOne for an undisclosed amount. The deal is expected to close in
Q4 2023, pending regulatory approval from the SEC.
"""
Finally, run the extraction and print the grouped results with confidence scores.
gliner_entities = extract_entities_gliner(earning_report, business_entities)
print("GLiNER Zero-Shot Entity Extraction:")
for entity_type, entities_list in gliner_entities.items():
if entities_list:
print(f"\n{entity_type.upper()} ({len(entities_list)} found):")
for entity in entities_list:
print(f" '{entity['text']}' (confidence: {entity['confidence']})")
Output:
GLiNER Zero-Shot Entity Extraction:
COMPANY (2 found):
'Apple Inc.' (confidence: 0.94)
'Apple' (confidence: 0.62)
QUARTER (3 found):
'third quarter' (confidence: 0.929)
'fourth quarter' (confidence: 0.948)
'Q4 2023' (confidence: 0.569)
FINANCIAL_FIGURE (5 found):
'$81.4 billion' (confidence: 0.908)
'$21.2 billion' (confidence: 0.827)
'$39.3 billion' (confidence: 0.875)
'$89 billion' (confidence: 0.827)
'$93 billion' (confidence: 0.817)
PERCENTAGE (1 found):
'2%' (confidence: 0.807)
EXECUTIVE (3 found):
'CEO' (confidence: 0.606)
'Tim Cook' (confidence: 0.933)
'Luca Maestri' (confidence: 0.813)
PRODUCT (1 found):
'iPhone' (confidence: 0.697)
LOCATION (1 found):
'Cupertino headquarters' (confidence: 0.657)
STARTUP (1 found):
'WaveOne' (confidence: 0.767)
REGULATORY_BODY (1 found):
'SEC' (confidence: 0.878)
GLiNER outperformed standard NER through zero-shot learning:
Extraction coverage: 18 entities vs spaCy’s mixed-category results
Classification accuracy: correctly distinguished companies from products/services/agencies
Domain adaptation: business-specific categories (startup, regulatory_body) vs generic classifications
Label flexibility: custom entity types defined through natural language descriptions
However, GLiNER missed some complex financial entities that span multiple words:
Stock symbols: Failed to recognize “NASDAQ: AAPL” as a structured financial identifier
Market trends: Captured “2%” but missed the complete context “up 2% year over year” as market_reaction
langextract: AI-Powered Extraction with Source Grounding
GLiNER’s limitations with complex financial entities highlight the need for more sophisticated approaches. langextract addresses these exact challenges by using advanced AI models to understand entity relationships and provide transparent source attribution.
Unlike pattern-based extraction, langextract leverages modern LLMs (Gemini, GPT, or Vertex AI) to capture multi-token entities like “NASDAQ: AAPL” and contextual relationships like “up 2% year over year.”
Setup Instructions
First, install langextract and python-dotenv for environment management:
pip install langextract python-dotenv
Next, get an API key from one of these providers:
AI Studio for Gemini models (recommended for most users)
Vertex AI for enterprise use
OpenAI Platform for OpenAI models
Save your API key in a .env file in your project directory:
# .env file
LANGEXTRACT_API_KEY=your-api-key-here
Now let’s load our API key and define the extraction schema:
import os
from dotenv import load_dotenv
import langextract as lx
from langextract import extract
# Load environment variables from .env file
load_dotenv()
# Load API key
api_key = os.getenv('LANGEXTRACT_API_KEY')
Now we’ll create the extraction function using the real langextract API:
def extract_entities_langextract(text):
"""Extract entities using langextract with proper API usage."""
# Brief prompt – let examples guide the extraction
prompt_description = """Extract business entities: companies, executives, financial figures, quarters, locations, percentages, products, startups, regulatory bodies, stock_symbols, market_reaction. Use exact text."""
# Provide example data to guide extraction with all entity types
examples = [
lx.data.ExampleData(
text="Microsoft Corp. (NYSE: MSFT) CEO Satya Nadella reported Q2 2024 revenue of $65B, down 5% quarter-over-quarter. The Seattle campus announced Azure cloud grew $28B. The firm bought ML startup NeuralFlow pending FTC review.",
extractions=[
lx.data.Extraction(extraction_class="company", extraction_text="Microsoft Corp."),
lx.data.Extraction(extraction_class="executive", extraction_text="CEO Satya Nadella"),
lx.data.Extraction(extraction_class="quarter", extraction_text="Q2 2024"),
lx.data.Extraction(extraction_class="financial_figure", extraction_text="$65B"),
lx.data.Extraction(extraction_class="percentage", extraction_text="5%"),
lx.data.Extraction(extraction_class="market_reaction", extraction_text="down 5% quarter-over-quarter"),
lx.data.Extraction(extraction_class="location", extraction_text="Seattle campus"),
lx.data.Extraction(extraction_class="product", extraction_text="Azure cloud"),
lx.data.Extraction(extraction_class="financial_figure", extraction_text="$28B"),
lx.data.Extraction(extraction_class="startup", extraction_text="NeuralFlow"),
lx.data.Extraction(extraction_class="regulatory_body", extraction_text="FTC"),
lx.data.Extraction(extraction_class="stock_symbol", extraction_text="NYSE: MSFT")
]
)
]
# Extract using proper API
result = extract(
text_or_documents=text,
prompt_description=prompt_description,
examples=examples,
model_id="gemini-2.5-flash"
)
return result
The extract() function takes three key inputs:
text_or_documents: The text or documents to analyze
prompt_description: Brief instruction listing entity types to extract
examples: Training data showing the model exactly what each entity type looks like
model_id: Specifies which AI model to use (Gemini 2.5 Flash)
The function returns a result object containing:
extractions: List of found entities with their text and classification
char_interval: Character positions for each entity in the source text
Source grounding data for verification and visualization
Finally, let’s extract entities from our business document:
# Define the earnings report locally for this section
earning_report = """
Apple Inc. (NASDAQ: AAPL) reported third quarter revenue of $81.4 billion,
up 2% year over year. CEO Tim Cook stated that Services revenue reached
a new all-time high of $21.2 billion. The company's board of directors
declared a cash dividend of $0.24 per share.
CFO Luca Maestri mentioned that iPhone revenue was $39.3 billion for
the quarter ending June 30, 2023. The company expects total revenue
between $89 billion and $93 billion for the fourth quarter.
Apple's Cupertino headquarters announced the acquisition of AI startup
WaveOne for an undisclosed amount. The deal is expected to close in
Q4 2023, pending regulatory approval from the SEC.
"""
# Extract entities with langextract
langextract_entities = extract_entities_langextract(earning_report)
print(f"Extracted {len(langextract_entities.extractions)} entities:")
# Group extractions by class using defaultdict
grouped_extractions = defaultdict(list)
for extraction in langextract_entities.extractions:
grouped_extractions[extraction.extraction_class].append(extraction)
# Display grouped results
for entity_class, extractions in grouped_extractions.items():
print(f"\n{entity_class.upper()} ({len(extractions)} found):")
for extraction in extractions:
print(f" '{extraction.extraction_text}'")
Output:
Extracted 21 entities:
COMPANY (1 found):
'Apple Inc.'
STOCK_SYMBOL (1 found):
'NASDAQ: AAPL'
QUARTER (4 found):
'third quarter'
'quarter ending June 30, 2023'
'fourth quarter'
'Q4 2023'
FINANCIAL_FIGURE (6 found):
'$81.4 billion'
'$21.2 billion'
'$0.24 per share'
'$39.3 billion'
'$89 billion'
'$93 billion'
PERCENTAGE (1 found):
'2%'
MARKET_REACTION (1 found):
'up 2% year over year'
EXECUTIVE (2 found):
'CEO Tim Cook'
'CFO Luca Maestri'
PRODUCT (2 found):
'Services'
'iPhone'
LOCATION (1 found):
'Cupertino headquarters'
STARTUP (1 found):
'WaveOne'
REGULATORY_BODY (1 found):
'SEC'
langextract’s AI-powered approach delivered superior extraction results:
Entity count: 21 entities vs GLiNER’s 17, with richer contextual detail
Sophisticated parsing: Extracted “quarter ending June 30, 2023” for precise temporal context
Business semantics: Understood stock_symbol format and market trend relationships requiring domain knowledge
For visual business documents like charts and graphs, consider multimodal AI approaches that can extract structured data directly from images.
However, GLiNER offers practical advantages for certain use cases:
Local processing: No API calls or internet dependency required
Cost efficiency: Zero usage costs after model download vs API pricing per request
Speed: Faster inference for high-volume document processing
Privacy: Sensitive documents never leave your infrastructure
Conclusion
This article demonstrated four progressive approaches to entity extraction from business documents, each building upon the limitations of the previous method:
Regex: Handles structured patterns (dates, amounts) but fails with variable text formats
spaCy: Processes standard entities reliably but misclassifies business-specific terms
GLiNER: Enables custom entity types without training but misses multi-token relationships
langextract: Captures complex business context and relationships through AI understanding
I recommend starting with regex for simple extraction, spaCy for standard entities, GLiNER for custom categories, and langextract when business context and relationships matter most.
💻 Get the Code: The complete source code and Jupyter notebook for this tutorial are available on GitHub. Clone it to follow along!
Related Tutorials
Text Matching: Build Text Matching That Actually Works (4 Tools Compared) for fuzzy string matching when business entities have variations
Document Processing: Transform Any PDF into Searchable AI Data with Docling for preprocessing PDF business documents before extraction
📚 Want to go deeper? Learning new techniques is the easy part. Knowing how to structure, test, and deploy them is what separates side projects from real work. My book shows you how to build data science projects that actually make it to production. Get the book →
Stay Current with CodeCut
Actionable Python tips, curated for busy data pros. Skim in under 2 minutes, three times a week.
.codecut-subscribe-form .codecut-input {
background: #2F2D2E !important;
border: 1px solid #72BEFA !important;
color: #FFFFFF !important;
}
.codecut-subscribe-form .codecut-input::placeholder {
color: #999999 !important;
}
.codecut-subscribe-form .codecut-subscribe-btn {
background: #72BEFA !important;
color: #2F2D2E !important;
}
.codecut-subscribe-form .codecut-subscribe-btn:hover {
background: #5aa8e8 !important;
}
.codecut-subscribe-form {
max-width: 650px;
display: flex;
flex-direction: column;
gap: 8px;
}
.codecut-input {
-webkit-appearance: none;
-moz-appearance: none;
appearance: none;
background: #FFFFFF;
border-radius: 8px !important;
padding: 8px 12px;
font-family: ‘Comfortaa’, sans-serif !important;
font-size: 14px !important;
color: #333333;
border: none !important;
outline: none;
width: 100%;
box-sizing: border-box;
}
input[type=”email”].codecut-input {
border-radius: 8px !important;
}
.codecut-input::placeholder {
color: #666666;
}
.codecut-email-row {
display: flex;
align-items: stretch;
height: 36px;
gap: 8px;
}
.codecut-email-row .codecut-input {
flex: 1;
}
.codecut-subscribe-btn {
background: #72BEFA;
color: #2F2D2E;
border: none;
border-radius: 8px;
padding: 8px 14px;
font-family: ‘Comfortaa’, sans-serif;
font-size: 14px;
font-weight: 500;
cursor: pointer;
text-decoration: none;
display: flex;
align-items: center;
justify-content: center;
transition: background 0.3s ease;
}
.codecut-subscribe-btn:hover {
background: #5aa8e8;
}
.codecut-subscribe-btn:disabled {
background: #999;
cursor: not-allowed;
}
.codecut-message {
font-family: ‘Comfortaa’, sans-serif;
font-size: 12px;
padding: 8px;
border-radius: 6px;
display: none;
}
.codecut-message.success {
background: #d4edda;
color: #155724;
display: block;
}
/* Mobile responsive */
@media (max-width: 480px) {
.codecut-email-row {
flex-direction: column;
height: auto;
gap: 8px;
}
.codecut-input {
border-radius: 8px;
height: 36px;
}
.codecut-subscribe-btn {
width: 100%;
text-align: center;
border-radius: 8px;
height: 36px;
}
}
Subscribe