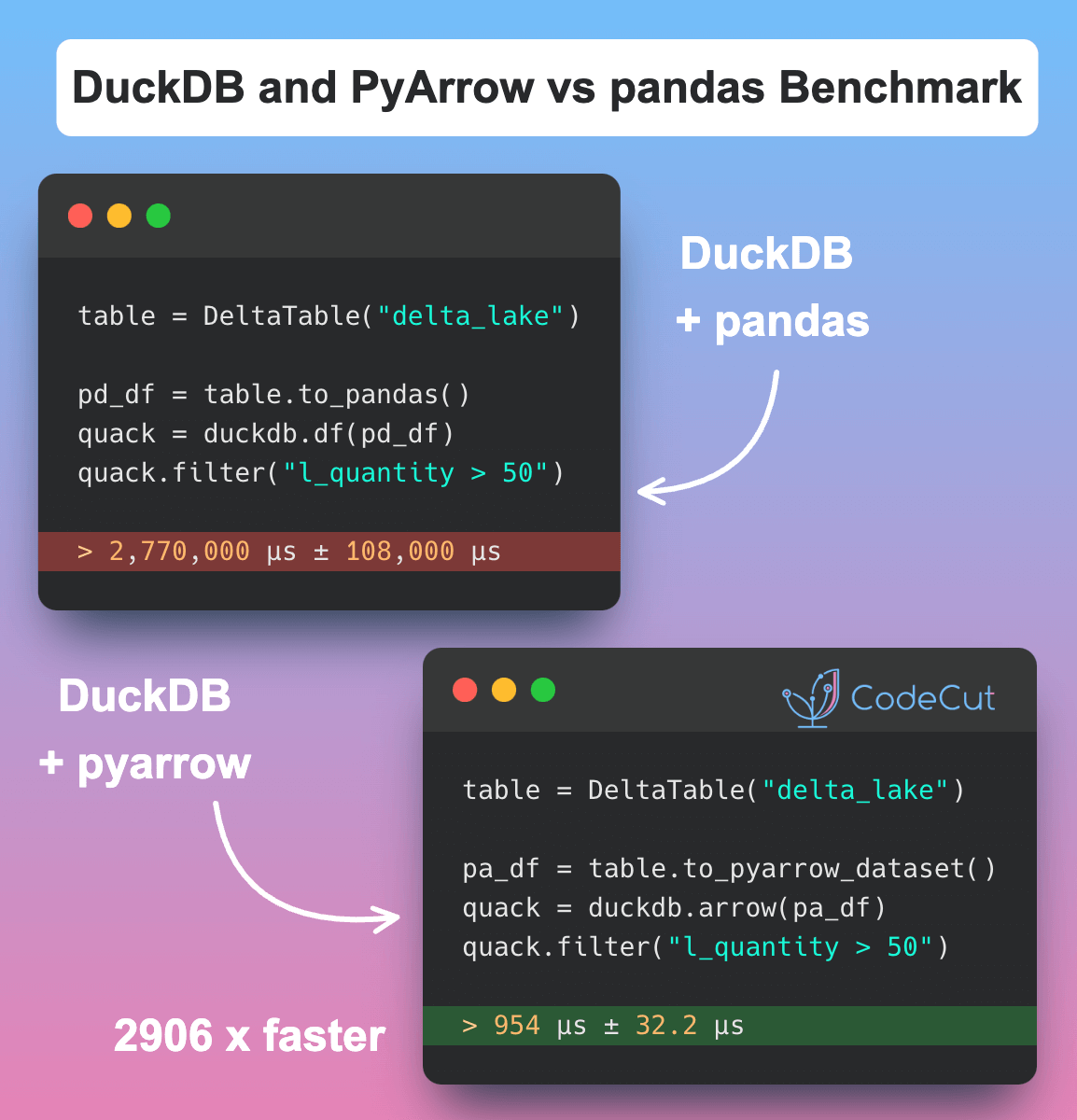
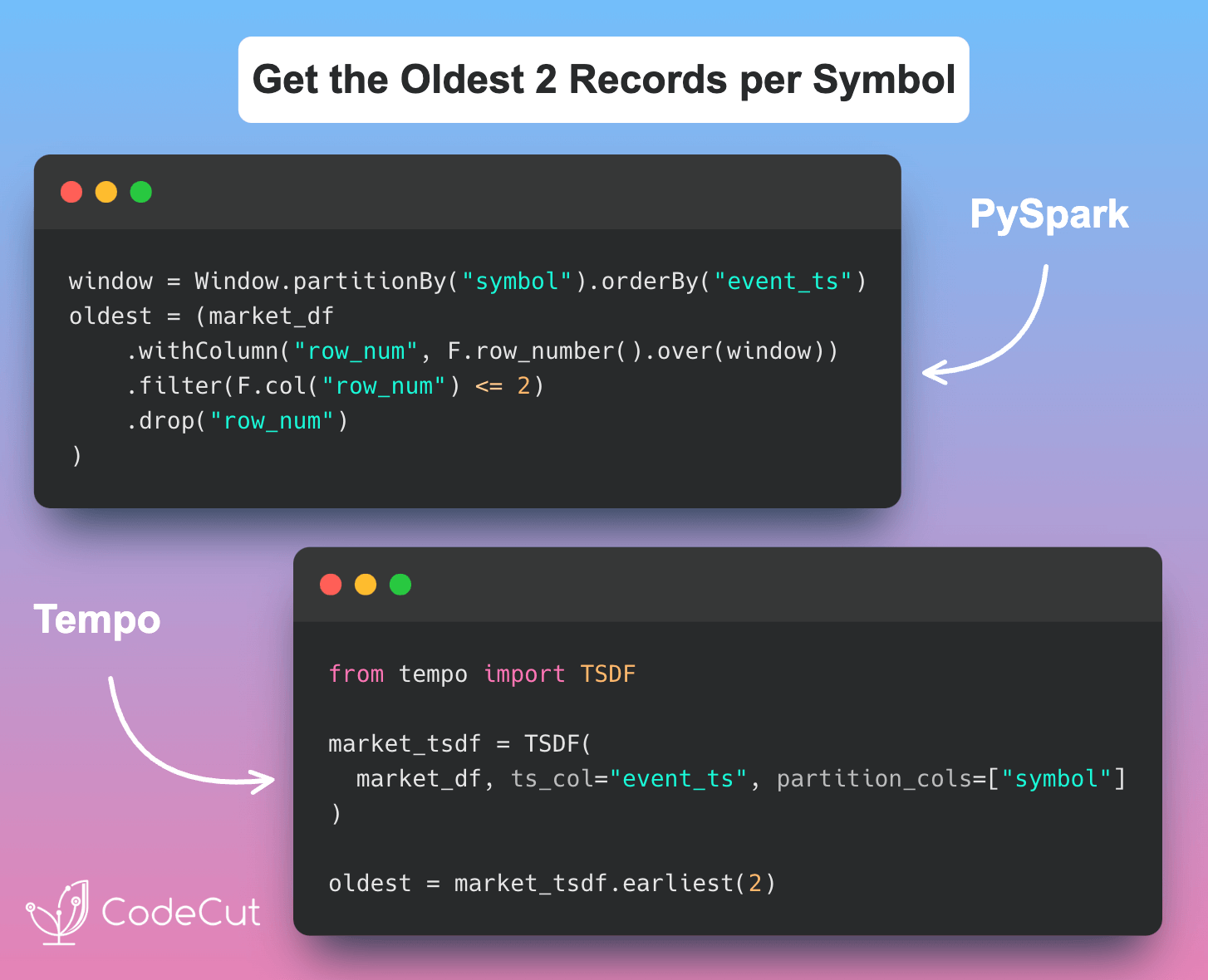
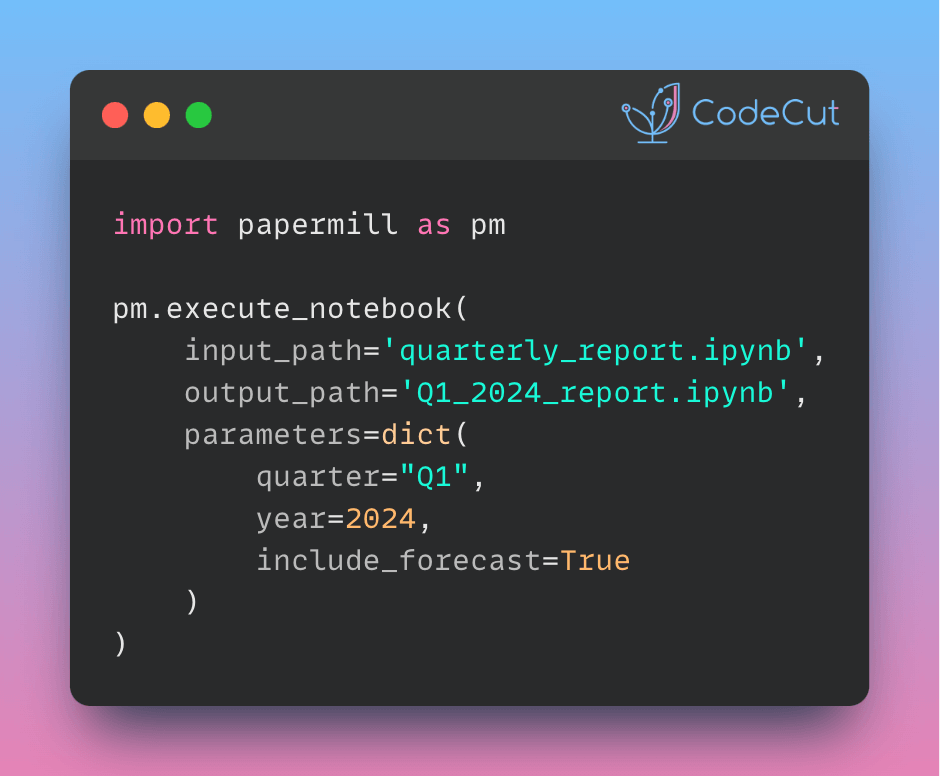
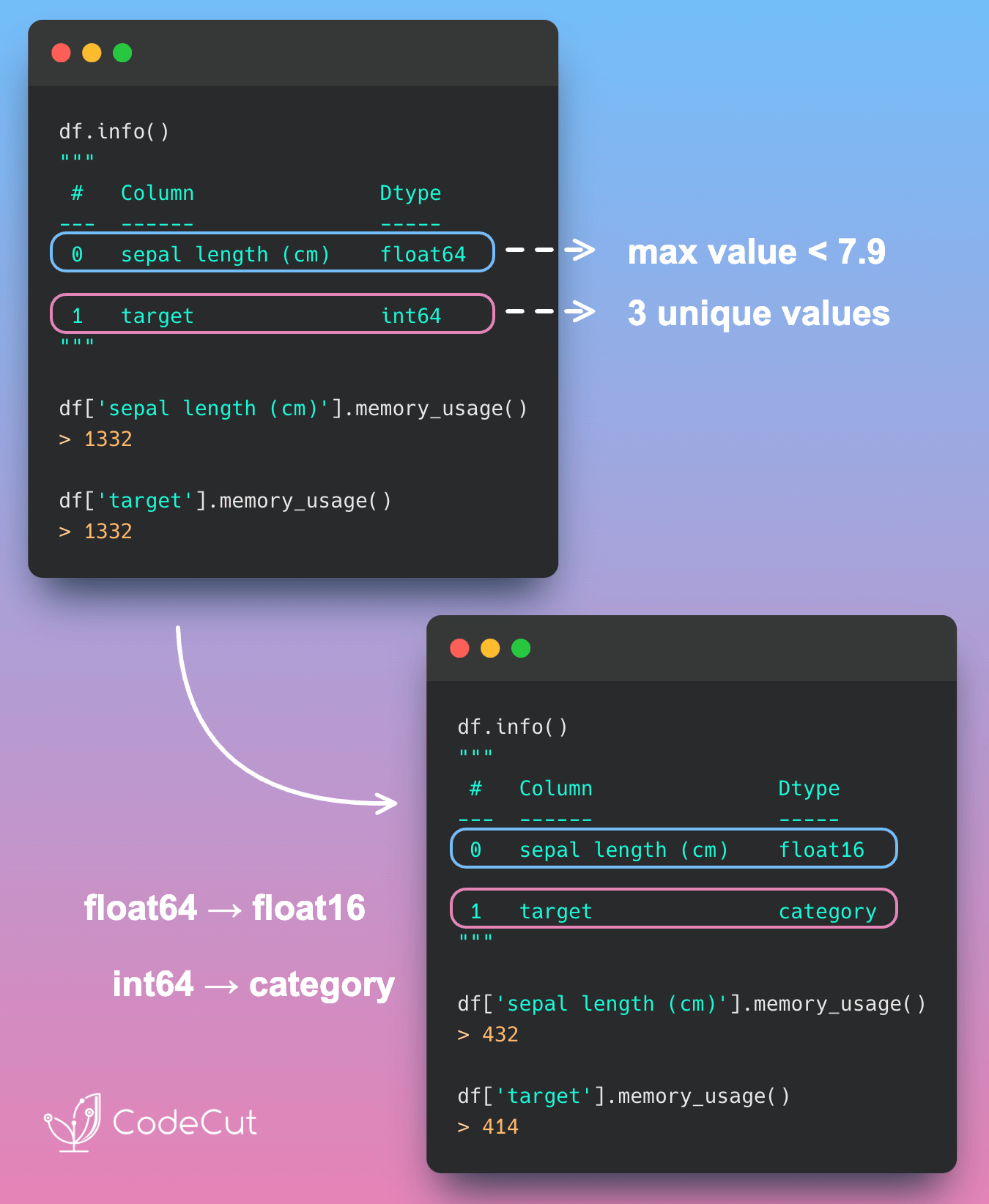
Data Analysis & ManipulationAnalyze DataManage DataFeature EngineerSQLMachine Learning & AIMachine LearningNatural Language ProcessingTime SeriesLLMCode QualityPython TipsPython-UtilitiesCode OptimizationDevOpsTestingGitCommand LineEnvironment ManagementBetter OutputsToolsNumPyPandasPolarsPySparkDelta LakeDuckDBJupyter NotebookVisualization & ReportingDashboardVisualizationWorkflow & AutomationWorkflow AutomationScrape DataX Faster Data Analysis with Polars: A Guide to Lazy Execution January 31, 2025 Validating Polars DataFrames with Pandera January 25, 2025 Fuzzy Joining Tables with Non-Exact Matching Entries January 24, 2025 Polars: Blazing Fast DataFrame Library January 9, 2025 Optimizing PySpark Queries with Nested Data Structures January 9, 2025 Simplify CSV Data Management with DuckDB January 9, 2025 Pandera: Data Validation Made Simple for Python DataFrames January 5, 2025 Building a High-Performance Data Stack with Polars and Delta Lake January 5, 2025 Best Practices for PySpark DataFrame Comparison Testing December 22, 2024 DuckDB + PyArrow: 2900x Faster Than pandas for Large Dataset Processing December 6, 2024 Tempo: Simplified Time Series Analysis in PySpark December 5, 2024 Transform Single Inputs into Tables Using PySpark UDTFs November 24, 2024 Automate Jupyter Notebooks with Papermill November 15, 2024 Euporie: Full-Featured Jupyter Notebooks in Your Terminal November 12, 2024 Smart Data Type Selection for Memory-Efficient Pandas November 11, 2024 « Previous Page1 Page2 Page3 Page4 Page5 Next »